

What anonymization techniques can you trust?
This post is part of a series on differential privacy. Check out the table of contents to see the other articles!
This article was first published on the Tumult Labs blog; its copyright is owned by Tumult Labs.
Let's say that we have some sensitive data, for example about people visiting a hospital. We would like to share it with a partner in an anonymous way: the goal is to make sure that the released data does not reveal anything about any one individual. What techniques are available for this use case?
Randomize identifiers
Obviously, if we leave names, or public user identifiers in our data (like people's telephone numbers or email addresses), then that's not going to be anonymous. So here is a first idea: let's hide this information! By replacing e.g. names with random numbers, identities are no longer obvious. This is called pseudonymization (or sometimes tokenization): identifiers are replaced with pseudonyms (or tokens). These pseudonyms are consistent: the same original identity is always replaced by the same pseudonym.
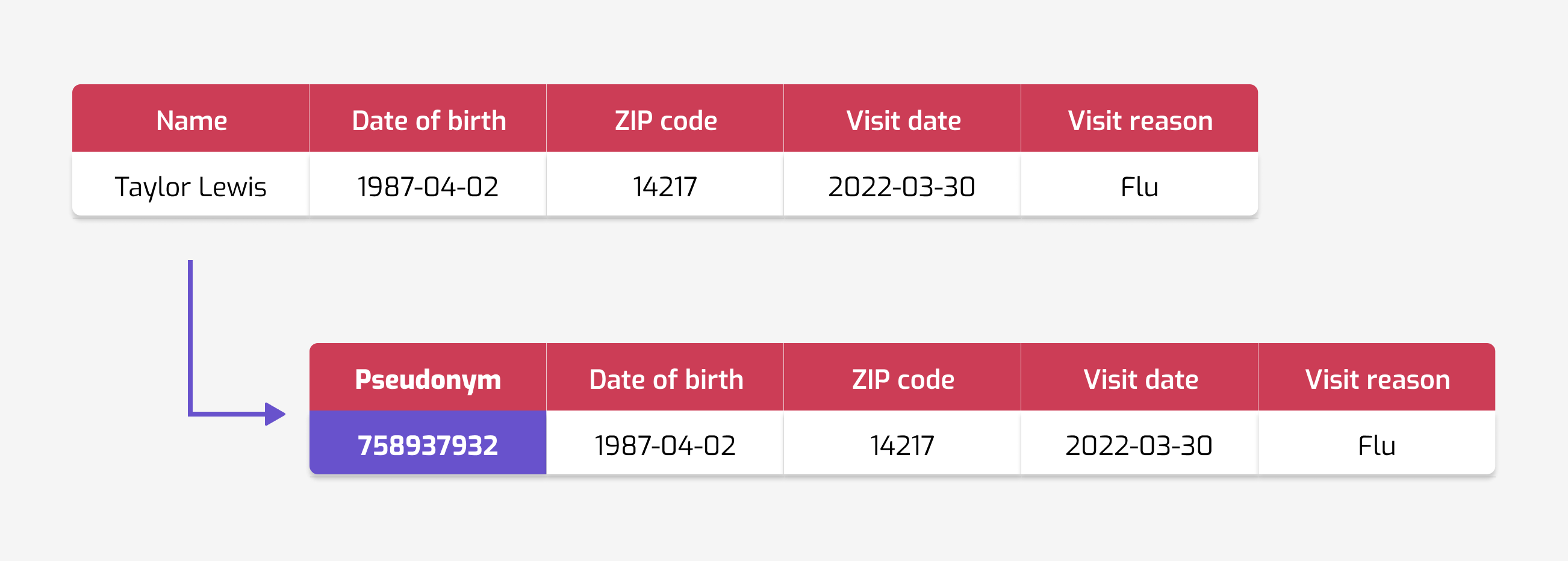
Unfortunately, "no longer obvious" is very different from "impossible to figure out". Randomizing identifiers often fails to protect the privacy of the people in the data. This can be because this randomization process itself is insecure. A good example is the New York taxi database data. The randomization process was done in a naive way… and this allowed researchers to reverse-engineer license plates from pseudonyms.
But there is a more fundamental reason why such schemes are unsafe: it's impossible to know for sure what can be used to re-identify someone. Direct identifiers are not the only thing that can be used to find out someone's identity. A famous example is the release of AOL search queries. AOL data scientists randomized all the identifiers. But the data itself was problematic: what you search for reveals a lot about you! It only took a few days for journalists to reidentify people, using only their search queries.
Even worse, otherwise-innocuous data can become identifying when combined with additional information. The Netflix Prize dataset provides a striking example of this fact. Netflix published pseudonymized data containing only movie ratings. These do not seem identifying… and yet, researchers could combine them with public reviews and recover users' identities.
Remove identifiers altogether
If pseudonymization doesn't work, what about de-identification? Instead of replacing direct identifiers with random numbers, we could redact them altogether. This technique, sometimes called masking, is very common.
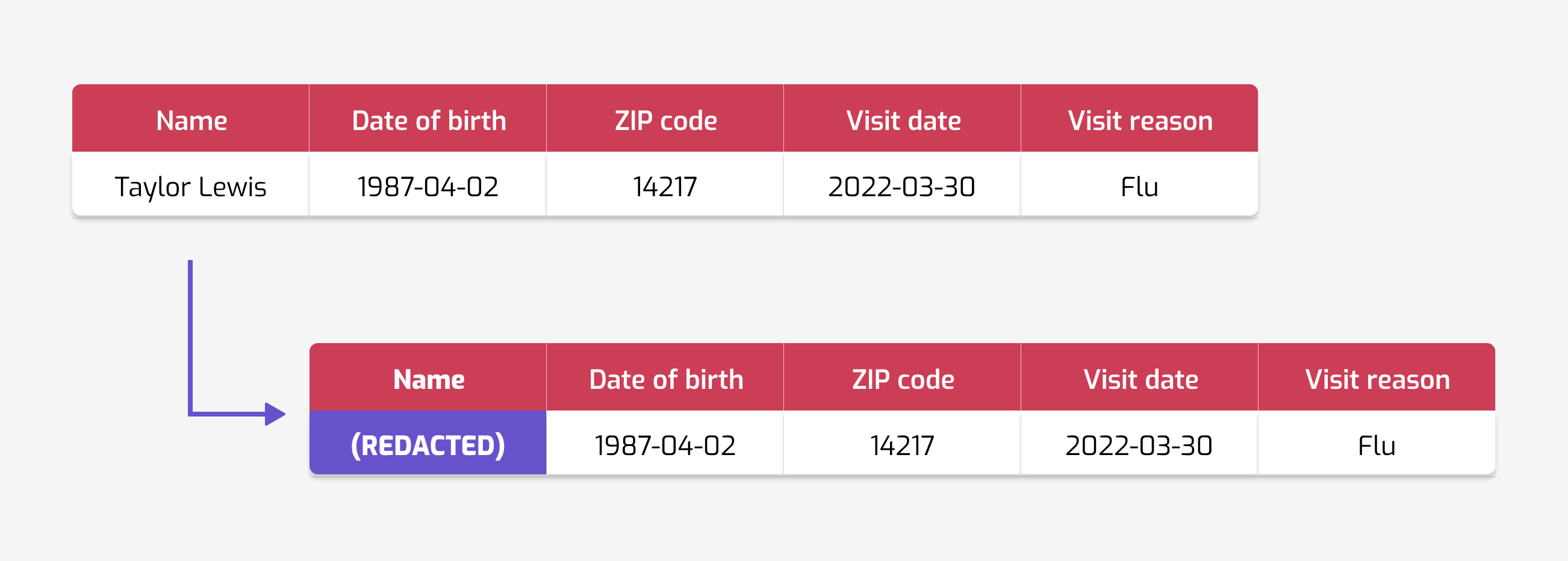
Unfortunately, masking provides little extra protection. The previous problem still applies: how can we know what information to redact and what to keep? Time and time again, data owners underestimate the reidentifiability of their data.
The Massachusetts state government gave us a first example of this phenomenon. In the 1990s, they released medical data about hospital visits, with names redacted. But this patient data contained key demographic information: ZIP codes, dates of birth, and sex. And these are enough to identify a large fraction of the population! Including the then-governor of Massachusetts… More than a little embarrassing. With more demographic attributes, reidentification risk skyrockets to up to 99.98%.
"Isn't this sort of obvious?" – Wired, 2007
A lot of data turns out to be identifying, besides demographic information. Credit card metadata, location information, or social interactions can be just as revealing. The problem is profound: there is no way to know what a malicious person might use to reidentify records in our data. The only safe choice is to redact all the data, which is not very useful.
Apply rule-based techniques
Since simpler techniques fail, we could try more complicated heuristics. Many of them appear in the literature, and are still in use today:
- adding some random perturbation to individual values;
- making some attributes less granular;
- suppressing records with rare values;
- and a myriad of others.
These techniques might seem less naive, but they still don't provide a robust guarantee.
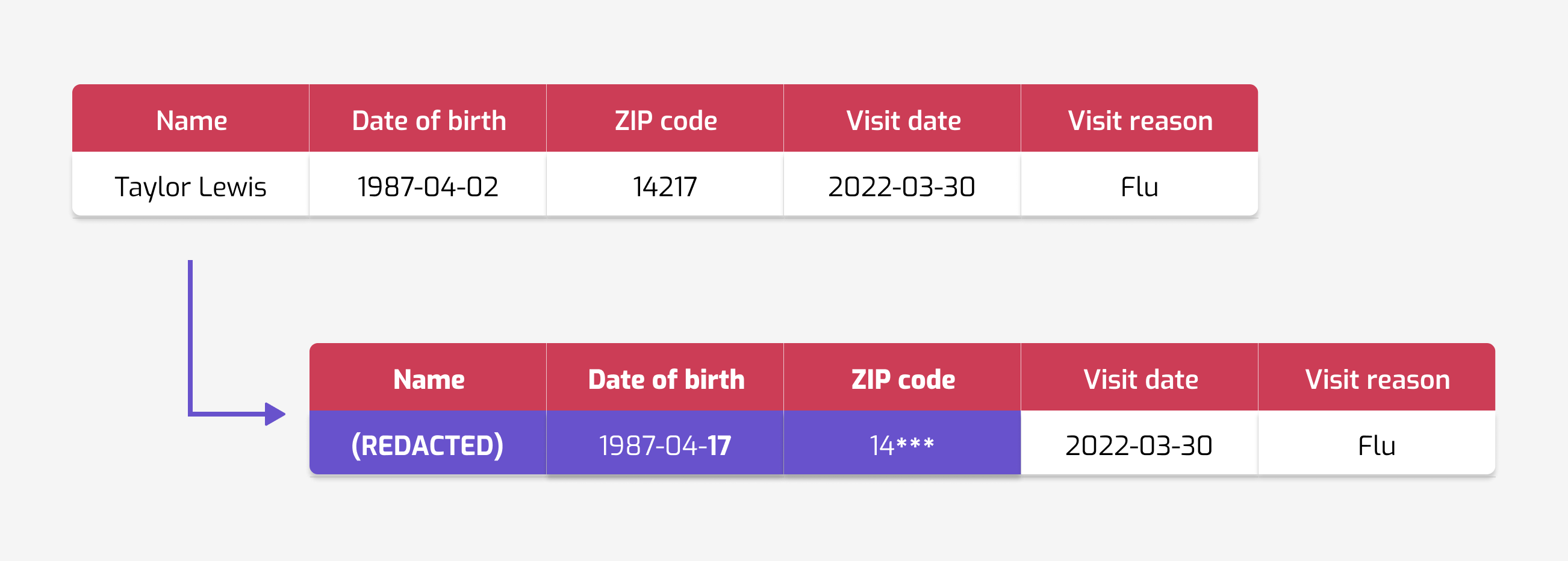
Even privacy notions from the scientific literature can fail to protect sensitive data. The first and most famous of these definitions is probably k-anonymity. Its intuition seems convincing: each individual is "hidden in a group" of other people with the same characteristics. Sadly, despite this intuition, k-anonymity fails at providing a good level of protection: downcoding attacks succeed at reidentifying people in data releases.
Aggregate the data
It seems like trying to look at each individual record to try to find out what to redact or randomize doesn't work. What if we aggregate multiple records together, instead? Surely releasing statistics across many people should be safe?
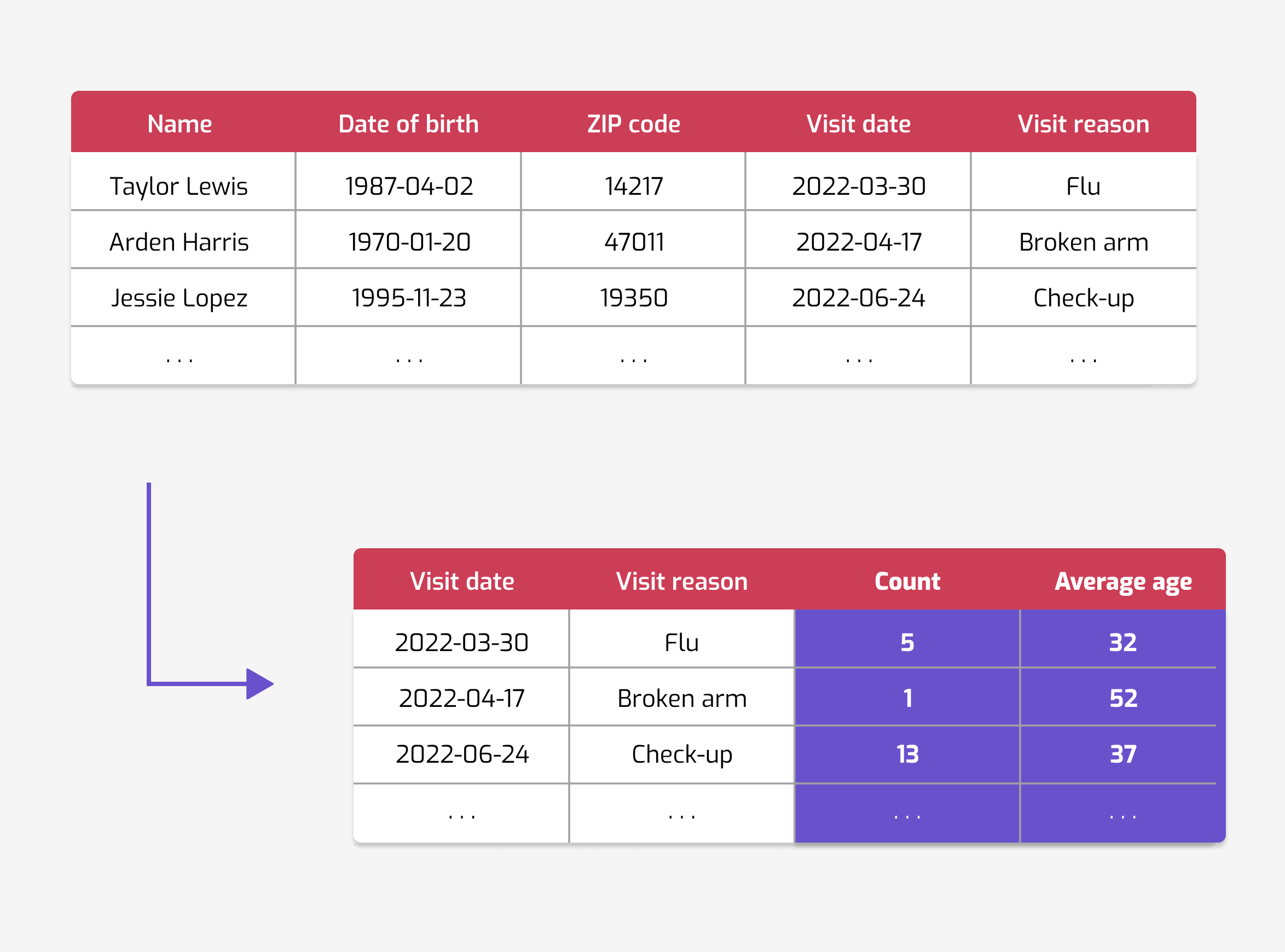
Sadly, this is still not the case: there are multiple ways that individual information can be retrieved from aggregated data. One of these ways uses the correlations present in the data. Consider a dataset counting how many people were in specific areas over time. This doesn't seem very identifying… Except human mobility data tends to be predictable: people travel approximately in the same direction between two points. This creates correlations, which attackers can then exploit: researchers managed to retrieve individual trajectories from such an aggregated dataset.
And there is another complication: it is often possible to combine multiple statistics and retrieve individual records. This technique is called a reconstruction attack. The most prominent example was done by the U.S. Census on the 2010 Decennial Census. The results speak for themselves! Worse still, reconstruction attacks are improving over time… so they could become even more of a risk in the future.
What do these attacks have in common?
Let's take a step back and look at all these failures of bad anonymization techniques. Are there some themes we can discern?
- Data is often more identifiable than it seems. Even a few innocuous-looking pieces of information can be enough to identify someone. And people tend to underestimate what data can be used to reidentify people in a dataset.
- Auxiliary data is a dangerous unknown variable. Information that seems secret might be public for certain individuals, or become known to attackers thanks to an unrelated data breach.
- Even "obviously safe" data releases are at risk. Successful attacks happen even on datasets that seem well-protected, like aggregated statistics.
- Attacks improve over time, in unpredictable ways. Mitigating only known
attacks, or performing empirical privacy checks, is not enough: using e.g.
newer AI techniques or more powerful hardware can break legacy protections.
What to do, then?
These failures of legacy techniques prove that we need something better. So, when does an anonymization method deserve our trust? It should at least address the four points in the previous section:
- it should avoid making assumptions on what is identifiable or secret in the data;
- it should be resistant to auxiliary data — its guarantee should hold no matter what an attacker might already know;
- it should provide a mathematical guarantee that doesn't rely on subjective intuition;
- and it should protect against possible future attacks, not just ones known today.
It turns out that this is exactly what differential privacy provides.
- It makes no assumptions on what a potential attacker might use in the data.
- Its guarantees do not depend on what auxiliary data the attacker has access to.
- It provides a quantifiable, provable guarantee about the worst-case privacy risk.
- And this guarantee holds for all possible attacks, so the guarantee is future-proof.
It has a host of other benefits, too. For example, it can quantify the total privacy cost of multiple data releases. It also offers much more flexibility: many kinds of data transformation and analyses can be performed with differential privacy.