

Mapping privacy-enhancing technologies to your use cases
This post is part of a series on differential privacy. Check out the table of contents to see the other articles!
This article was first published on the Tumult Labs blog; its copyright is owned by Tumult Labs.
Say you're working on a new project involving sensitive data — for example, adding a new feature to a healthcare app. This feature is bringing new privacy concerns that you're trying to grapple with. Maybe your lawyers aren’t feeling great about the compliance story of the app you're building. Maybe you want to make strong statements to users of the feature, about how you will handle their data. Maybe you’re afraid that sensitive user data might leak in unexpected ways. You’ve been hearing about advances in privacy technologies, and you wonder: should I look into one of those to see if it could solve my problem?
You've come to the right place. In this blog post, we'll walk you through a few key data handling use cases, each involving significant privacy challenges. We'll then map various privacy-enhancing technologies (PETs) to those use cases. Spoiler alert, the overall map of use cases and PETs will look like this:
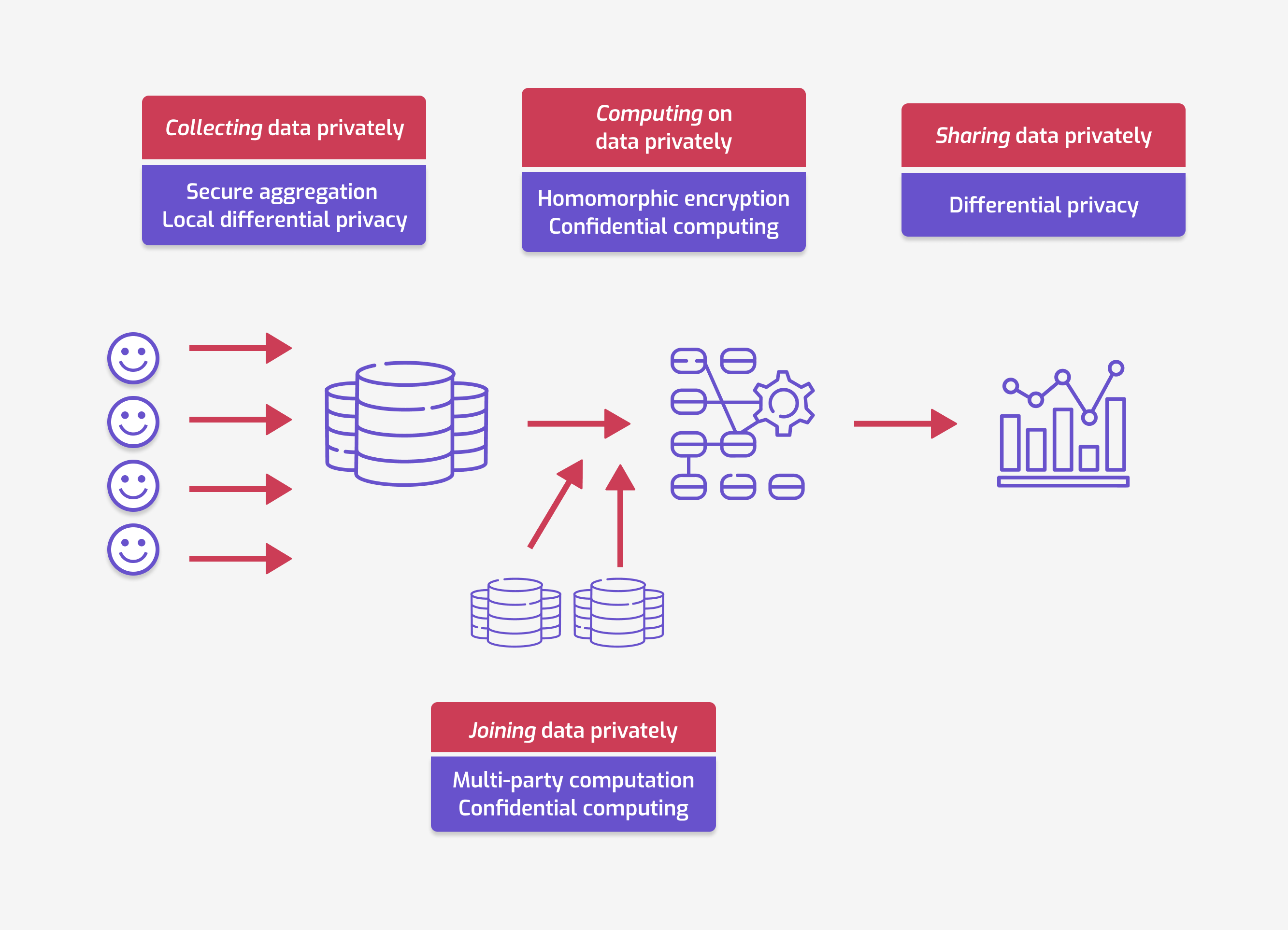
To better understand these challenges, we will make the adversarial model explicit as we discuss each use case. This means answering two questions:
- Who has access to the raw, privacy-sensitive data?
- Who are we protecting against; who must not be able to access the raw data?
In each diagram, we will label the entities with access to the data with a ✅, and the adversaries with a ❌.
Let’s go through each of these categories of use cases one by one.
Collecting data privately
For this use case, your goal is to collect data from individual users of your app. For example, let's say that you want to measure some metric related to health information among your user base. But there's a catch: you don’t want to collect personal data. Instead, you want to be able to tell your users: "I am not collecting data about you — I am only learning information about large groups of users."
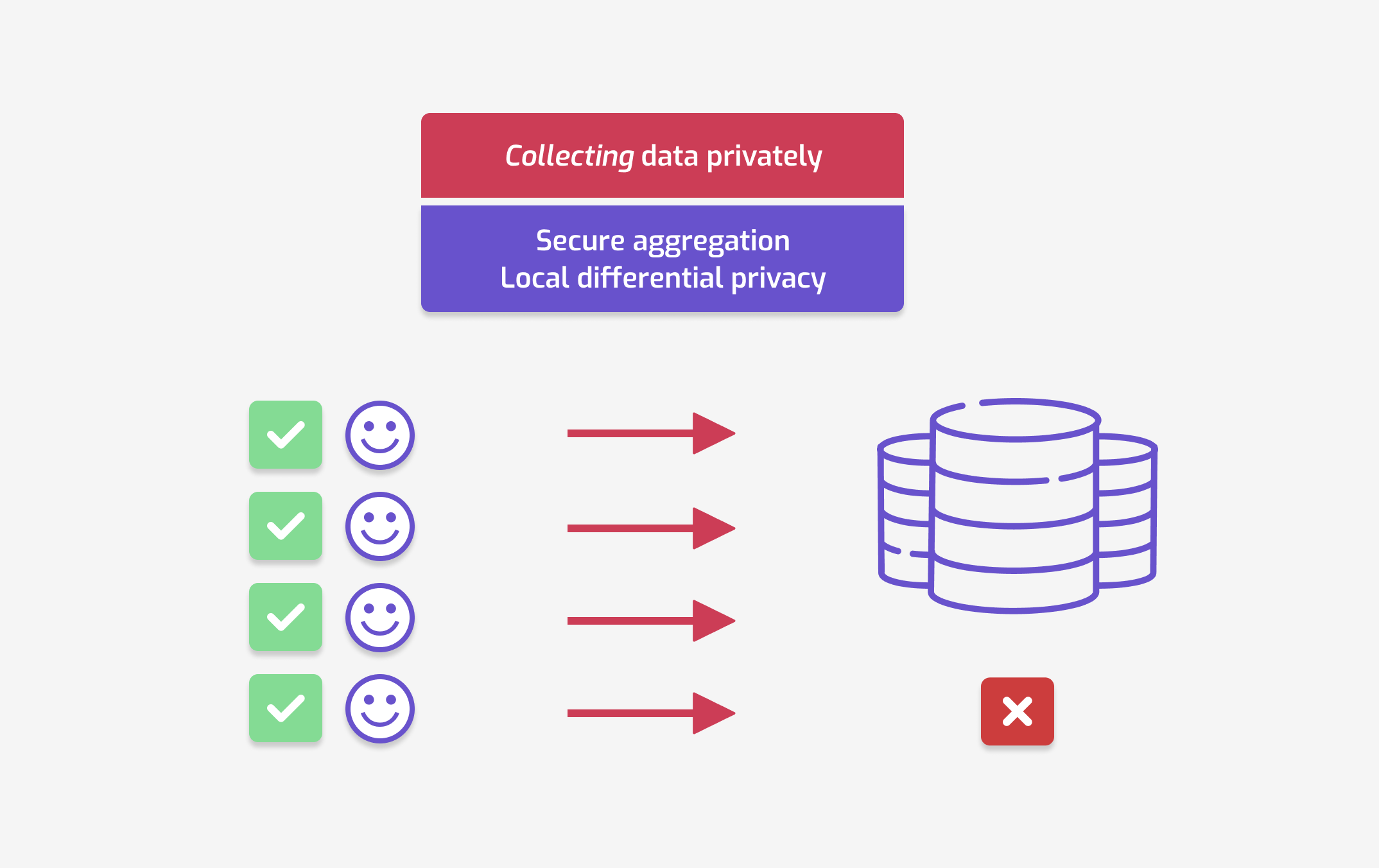
The adversarial model is as follows.
- Only individual users have access to their own raw data.
- You — the organization collecting the data — must not be able to see individual data points.
Note that in the diagram above, each user has access to their own data, but presumably not the data from other users.
Can you still learn something about aggregate user behavior in this context? Perhaps surprisingly, the answer is yes! There are two main privacy technologies that can address this use case.
- Secure aggregation1 consists in hiding each individual value using cryptographic techniques. These encrypted data points are then combined to compute the aggregate result.
- Local differential privacy consists in adding random noise to each individual data point. This noise hides the data of each person… but combining many data points can still reveal larger trends.
Both technologies can work together, and complement each other well. Local differential privacy provides formal guarantees on the output, at the heavy cost in accuracy. But combining it with secure aggregation can avoid most of this accuracy cost, and boost utility while preserving strong guarantees.
Federated learning is a common use case for these techniques. With this machine learning technique, model training happens on each user’s device. This can be better for privacy than sending the raw data to a central server… but model upgrades from each user can still leak sensitive information! Using secure aggregation and/or local differential privacy mitigates this risk.
Computing on data privately
For this use case, your goal is to have a partner run computations on your sensitive data, but hide the data from this partner. For example, in our healthcare app story, let’s say you collected some sensitive data through the app. A partner company has built a prediction model that you want to use on this data. You want them to run their model on your data, but you don’t want them to be able to access your data directly.
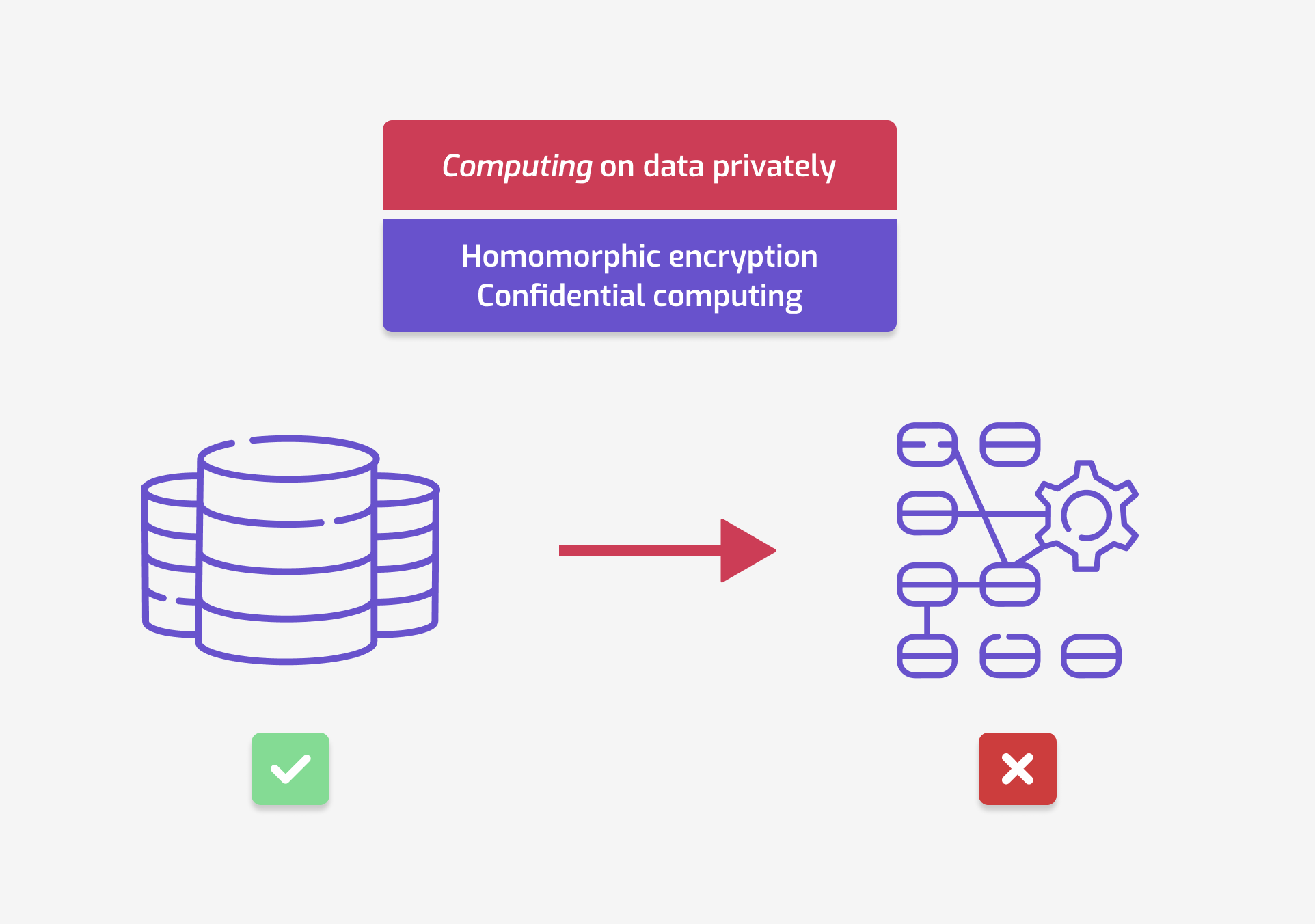
The adversarial model is as follows.
- You – the institution collecting the data – have access to the sensitive data.
- The organization performing the computation must not be able to access this data.
Two main technologies address this use case.
- Homomorphic encryption consists in encrypting the data before performing the computation. The organization must adapt its computation to work on encrypted data. Then, they send you back the result in encrypted form, and you can decrypt it to see the result.
- Confidential computing2 is a hardware-based approach to encrypt data while in-use. It can be combined with remote attestation: this technique allows you to verify that only the code that you have approved is running on your data.
The guarantee offered by homomorphic encryption is stronger: you do not need to trust that the hardware is correctly secured. However, these stronger guarantees come at a cost: homomorphic encryption often has a very large performance overhead.
Joining data privately
For this use case, your goal is to combine your data with the data from other organizations. For example, in our healthcare app, you might want to count how many of your users also use another app, made by a different company. Or you want to measure correlations between metrics in both apps. But like before, you don’t want anybody else accessing your data directly. And you don’t want to see the data from the other organizations, either!
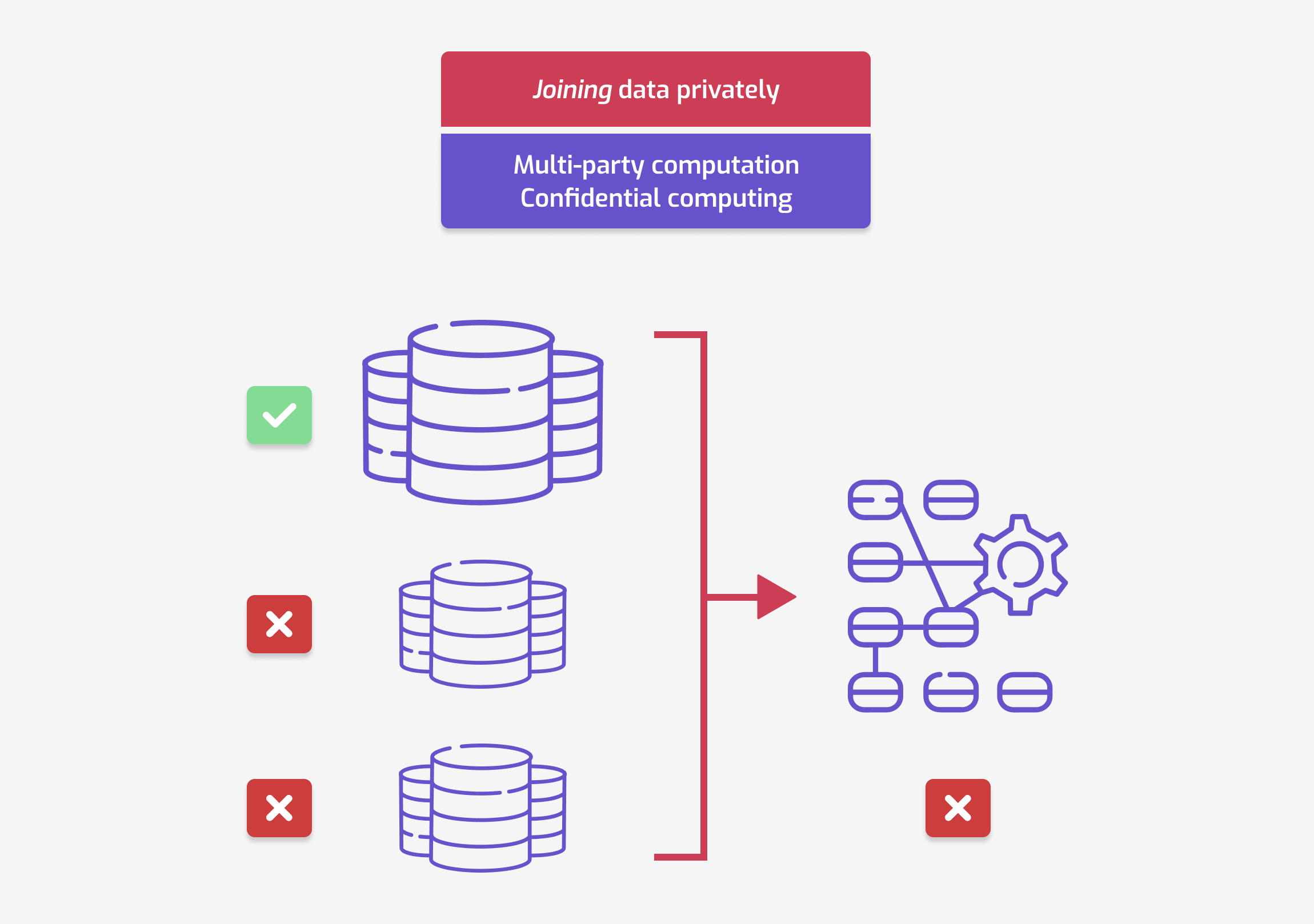
The adversarial model is as follows.
- You have access to your sensitive data (and only yours).
- Other organizations must not be able to access it. The platform running the computation (if any) must also not be able to access it.
What about the output of the computation — who can access it? It depends. In some cases, all participating organizations can access the results. In others, only some organizations can see them.
There are two main technologies that address this use case.
- Secure multi-party computation consists in each participant first encrypting their own data. Then, participants use a cryptographic protocol to compute the metric of interest.
- Confidential computing2 uses hardware modules to encrypt data while in-use. Like before, it works best when combined with remote attestation: then, every participant can verify that only approved code is running on their data.
Note that these techniques are sometimes not enough to protect the original data: the result of the computation can in itself leak something sensitive about the data! And this is the perfect transition for our next use case…
Sharing data privately
Finally, for this use case, your goal is to analyze your data, and share some insights about it. Here, sharing can mean very different things.
- Internal sharing: employees from another department of your organization might want to use your app metrics to inform the design of a different product. However, sharing personal data would require explicit consent in your privacy policy: your compliance story requires that you correctly anonymize metrics, even for internal use.
- External sharing: researchers from a partner university might want to use data from your app for a scientific study. Your goal is to share insights with them, without allowing them to see individual information.
- Publication: you might want to show some aggregated metrics in the app itself as part of a feature. In this case, all users of your app can see these metrics: it’s critical that they don't inadvertently reveal private information.
Removing identifiers is, of course, not enough to mitigate privacy risk. How do you enable such use cases without revealing individual information?
The adversarial model is as follows.
- You have access to the sensitive raw data.
- People who can see the shared data cannot use it to learn information about individuals.
There is one main technology that addresses this use case. If you're reading this blog post series, you certainly know what it is: differential privacy3. It adds statistical noise to aggregated information and provides strong privacy guarantees. You can use differential privacy for different kinds of data releases:
- statistics or other aggregated analyses on the original dataset;
- machine learning models trained on the sensitive data;
- or synthetic data, which has the same format as the original data.
This is what me and my colleagues at Tumult Labs are focusing on, building open-source software and providing solutions to tailored to our customer's needs. Reach out if that sounds like something you could use!
Final comments
Handling sensitive data comes with many challenges. In this blog post, I've listed a few major use cases, and the privacy technologies that address them. I omitted some other privacy-enhancing technologies, for two distinct reasons.
- Some approaches for the use cases we’ve seen do not provide any robust privacy guarantee. For example, some providers address the "joining data privately" use case without provable guarantees: instead, they simply present themselves as trusted third-parties. The situation is similar for the "sharing data privately" use case: some providers focus on ad hoc anonymization techniques. These do not make it possible to formally quantify privacy risk, and often fail in practice.
- Some technologies address more niche or infrequent use cases. For example, zero-knowledge proofs are mainly useful in cryptocurrency/blockchain applications. Private information retrieval can make a database accessible to clients, without being able to learn which part of the data these clients are querying. And there are others: privacy technology is a big space, with constant innovation.
-
Sometimes called federated analytics. ↩
-
The term "confidential computing" has several synonyms and related concepts.
- Trusted execution environments refer to the hardware modules used in confidential computing.
- Trusted computing uses the same kind of hardware modules as confidential computing. But in trusted computing, the context is different: end users, rather than organizations, are running the hardware module on their devices. Digital rights management is a common use case for this setting.
- Data cleanrooms is a more generic term for confidential computing: it also includes more ad hoc solutions that do not use trusted hardware modules.
-
Which, here, is used as a shortcut for central differential privacy. This isn't the most explicit, but is often done in practice. ↩