

Is differential privacy the right fit for your problem?
This post is part of a series on differential privacy. Check out the table of contents to see the other articles!
This article was first published on the Tumult Labs blog; its copyright is owned by Tumult Labs.
Say you have some sensitive data, like a batch of financial information about first-time home buyers applying for mortgages in Chicago. You would like to publish this data, or share it with third parties, for example to facilitate economic research. This financial data has sensitive information about individuals, so you need to make sure that you’re not revealing personal data.
So far, this seems like a perfect use case for differential privacy (DP): publishing trends without revealing information about individuals is exactly what it was designed for. You know that DP will successfully protect this individual data – its guarantees apply regardless of the data distribution. But you might still be wondering: will I succeed in publishing useful data? Will it be accurate enough for the people who will use it?
In this blog post, I’ll help you get an initial idea of whether differential privacy can work for you, using a simple litmus test. Spoiler alert: the process looks like this.
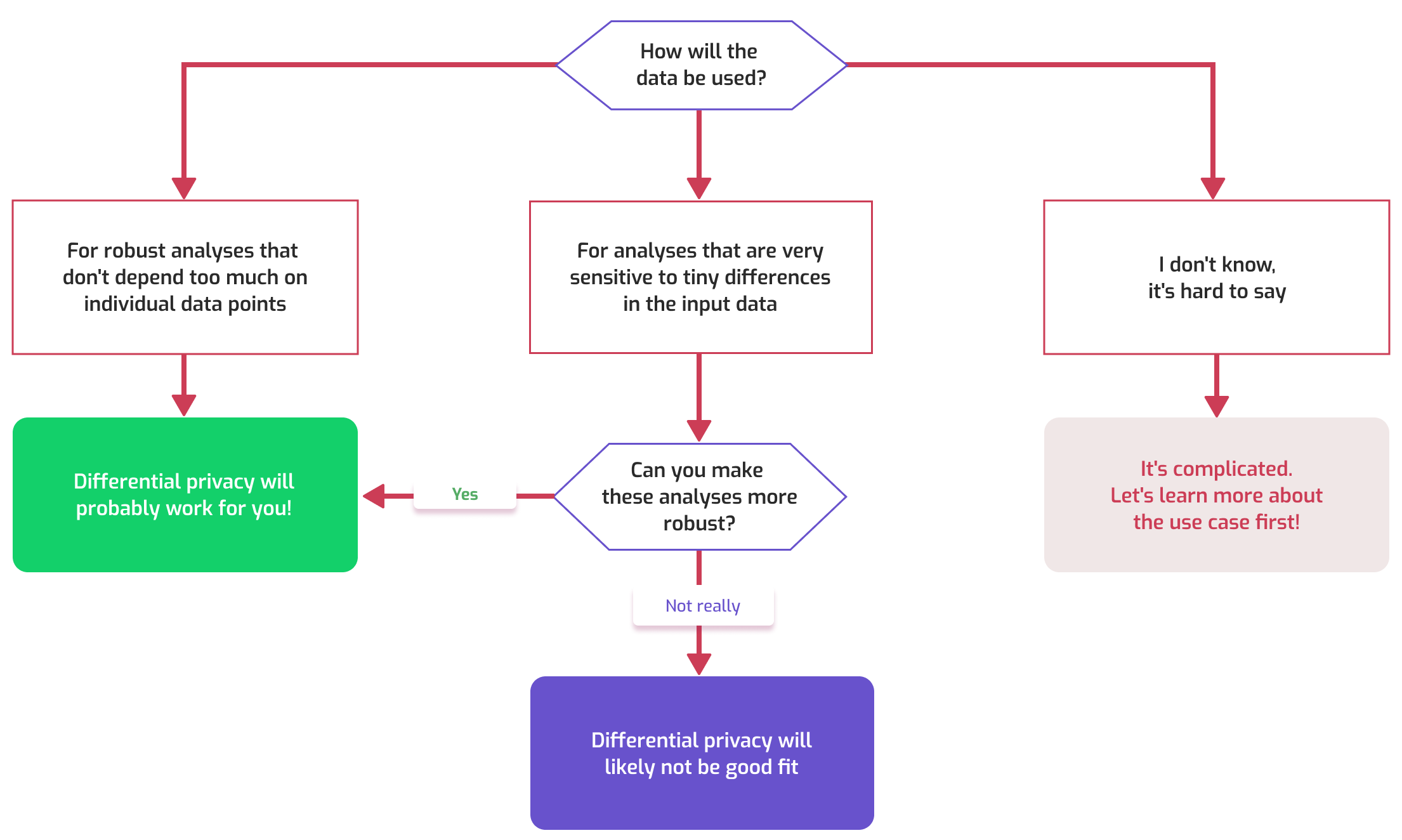
A simple litmus test
Consider the decisions people will make based on the published data, and ask yourself the following question.
Take the financial data scenario involving first-time home buyer data. Suppose that a single home-buyer's info was removed from the dataset – would that change the analysis you are doing on the data? If the analysis is about median value of mortgages in Chicago overall, probably not. But if the analysis is about the maximum value of mortgages in just one ZIP code, then removing that maximum value might change the result by quite a lot!
There are three possible answers to this question.
- The results of the analysis do not depend too much on small changes in the data. In this case, we say that the data analysis is robust, and differential privacy will likely work for you.
- The analysis might be very sensitive to small changes. In this case, it’s worth asking: can we make the analysis more robust? If not, then differential privacy is likely not a good fit.
- Finally, it might not be clear what the data will be used for, and whether these analyses will be robust. Then, we need to answer this question first, and learn more about the use case.
Let’s look more closely at these three options.
Robust analyses: well-suited to differential privacy
Robust analyses are those that do not depend too much on individual changes in the data. Many common data analyses are robust; in particular, almost all applications that aim at capturing trends fall in that category. For example, if you are…
- … estimating large population sizes (> 100)
- … understanding correlations between features in a large dataset
- … producing usage metrics for a service with many users
- … computing statistics over large groups
… then the result of these analyses won’t be impacted by very small changes in the data.
In that case, differential privacy will likely work for you. Robust analyses are a particularly good fit for DP techniques: you will likely be able to generate high-quality data with strong privacy protections. The decisions made using the DP data will closely resemble those that would have been made on the true data.
This makes sense: DP is all about adding small amounts of jitter to computations to hide the data of single individuals. But DP doesn’t need a lot of jitter: the perturbation’s magnitude is similar to the impact of a single person. If a single person is unlikely to change the result of future data analyses… differential privacy probably won’t change it too much, either.
Note that this litmus test tells you about feasibility. It doesn’t always mean that deploying DP will be very easy. Some use cases, like machine learning, or situations where you want to release a lot of statistics, can be tricky. In any case, my colleagues & I at Tumult Labs can help! Don’t hesitate to reach out.
Analyses that are sensitive to small changes in the data
Some analyses are very sensitive to the data of single individuals: a change in a single person’s data can change the outcome drastically! This typically happens in three cases.
Small populations
Suppose that you are trying to publish the average mortgage value for a specific ZIP code, there are only a few first-time home buyers – say, fewer than 10. In this case, an individual change might have a large impact on the average!
In situations such as this one, individual changes can have a large impact on the decisions made with the data. In this case, the noise added by differential privacy is also likely to change the result of the analysis. This will often be unacceptable: DP will not be a good fit.
Finding outlier individuals
Suppose that you are trying to find which people had mortgages that were significantly above the average in their area. In applications like this one, the goal is to detect outlier behavior. This is at odds with the fundamental goal of differential privacy: hiding information about all individuals, including outliers! In this kind of scenario, another approach might be needed.
Preserving linkability
Suppose that you want to enable other people to run analyses joining your data with their own data, at the level of each individual. In that case, you need a one-to-one relationship between people in the original data and in the output data. This is also at odds with differential privacy: you cannot hide who is present in the sensitive dataset and also preserve linkability. Small changes in the data will be clearly visible, since one user will or will not be part of the output.
Making the analysis more robust
When the analysis is sensitive to small changes in the data, it is worth asking: could we change that? Can we reformulate the problem in a more robust way? Doing so can often be doubly beneficial, and lead to privacy and utility improvements.
Say that the published data will be used to determine the impact of age on the rejection rate for mortgages. A first approach would be to release rejection rates, grouped by age. But some values of age are rarer than others: we might have many data points where the age is 40, but only a handful where the age is 20.
For these outlier values, small changes in the data might lead to large changes. But we are not interested in specific age values, only about the global relationship between age and rejection rate. Thus, we could change our strategy to publish data for age ranges, so each statistic comes from more data, and is more robust to small changes. This would make the released data more trustworthy, and the publication process more amenable to differential privacy.
For use cases that appear to require linkability, ask yourself the question: can we perform the join between datasets before computing the statistics of interest? If so, then using differential privacy might be an option.
What if I don’t know how the data will be used?
Sometimes, the question from our litmus test might be difficult to answer: what decisions will be made based on the published data? You might know that other people want access to this data, but not know exactly what they will want to do with it.
The right thing to do, then, is to try and understand more about their use case. The more you know what they want to do, the easier it will be to design a solution that works for them. This is both to answer our question about feasibility, and to help craft the requirements for a possible DP-based solution. The more you understand the requirements of your stakeholders, the happier you and they will be with the released data.
Thanks to Ashwin Machanavajjhala, Gerome Miklau, and Nicole Le for helpful feedback on this post.