

A list of real-world uses of differential privacy
This post is part of a series on differential privacy. Check out the table of contents to see the other articles!
This article is a list of real-world deployments of differential privacy, along with their privacy parameters. One day, we might have a proper Epsilon Registry, but in the meantime…
First, some notes.
- The main list only includes projects with a publicly documented value of the privacy parameters, including about what the privacy unit is. Projects that don't publish this information, but mention using DP, are listed at the end.
- All use cases use central DP unless specified otherwise.
- The list is sorted by alphabetical order of the organization publishing the data.
- When a project uses open-source differential privacy tooling, I added a link to it.
- I also added some caveats and general comments at the end of this post.
If you'd like to add or correct something, please let me know! My contact info is at the bottom of this page.
Apple
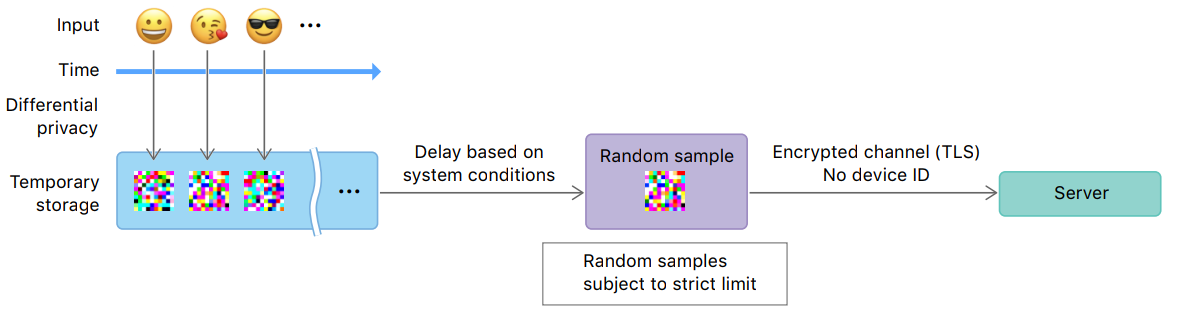
Apple uses local DP to collect some data from end-user devices running iOS or macOS. The process is documented in a high-level overview document and a detailed paper. All use \(\varepsilon\)-DP, the values of the privacy parameter are described below, with a privacy unit of user-day.
- QuickType suggestions learns previously-unknown words typed by sufficiently many users, using \(\varepsilon=16\).
- Emoji suggestions calculates which emojis are most popular among users, using \(\varepsilon=4\).
- Lookup hints collects data on actions taken from iOS Search suggestions. (I think. It's not very explicit.) It uses \(\varepsilon=8\).
- Health Type Usage estimates which health types are most used in the HealthKit app, using \(\varepsilon=2\).
- Safari Energy Draining Domains and Safari Crashing Domains collect data on web domains: which domains are most likely to cause high energy consumption or crashes, respectively. Both features use a common budget of \(\varepsilon=8\).
- Safari Autoplay Intent Detection collects data about websites that auto-play videos with sound: in which of these domains are users most likely to mute vs. keep playing the video? It uses \(\varepsilon=16\).
Full URLs Data Set
The Full URLs Data Set provides data on user interactions with web pages shared on Facebok. The privacy unit is each individual action: this can be e.g. "Alice shared URL foo.com", or "Bob viewed a post containing URL bar.org". For each type of action, the privacy parameter is chosen to protect 99% of users with \((\varepsilon,\delta)\)-DP, for \(\varepsilon=0.41\) and \(\delta=10^{-5}\). Across all metrics, 96.6% of users are protected with \((\varepsilon,\delta)\)-DP with \(\varepsilon=1.69\) and \(\delta=10^{-5}\).
Movement Range Maps
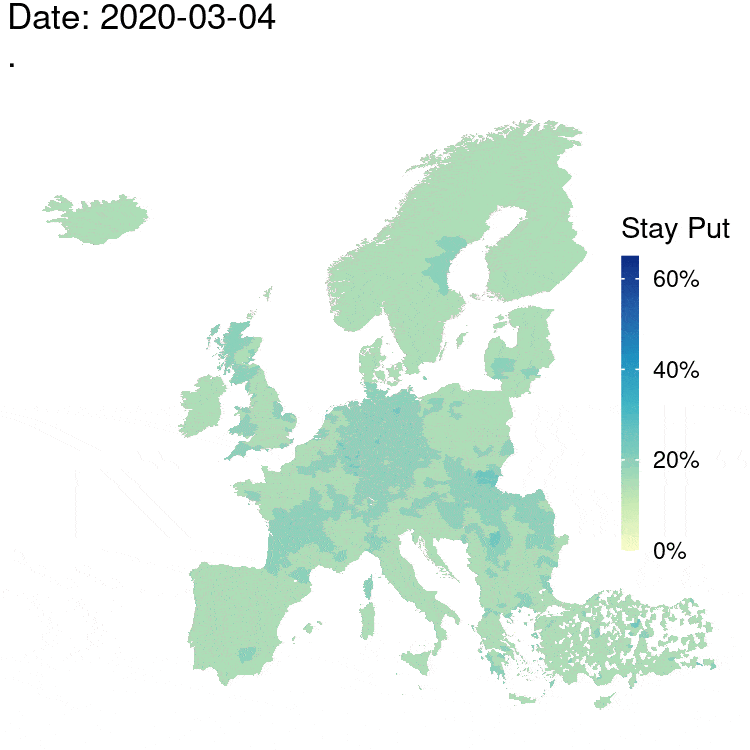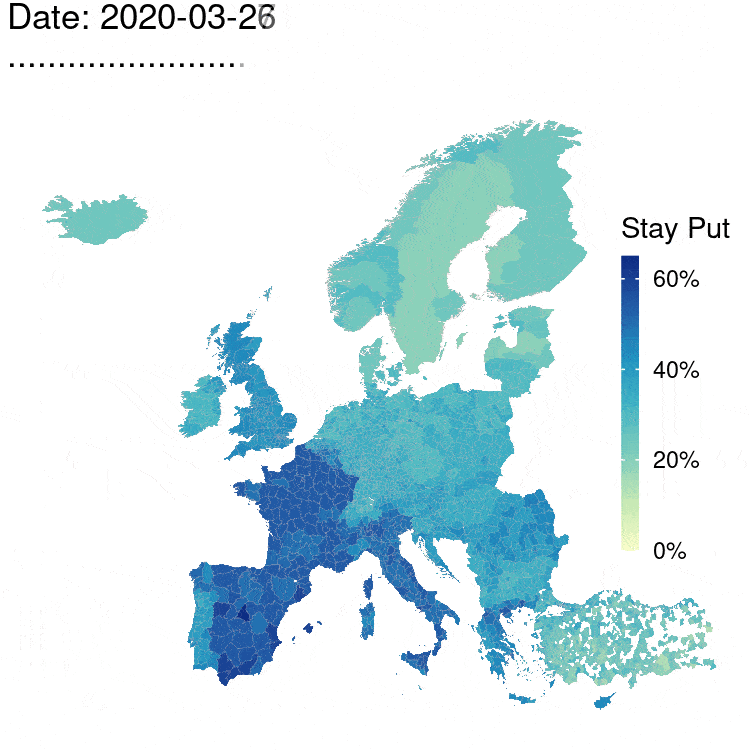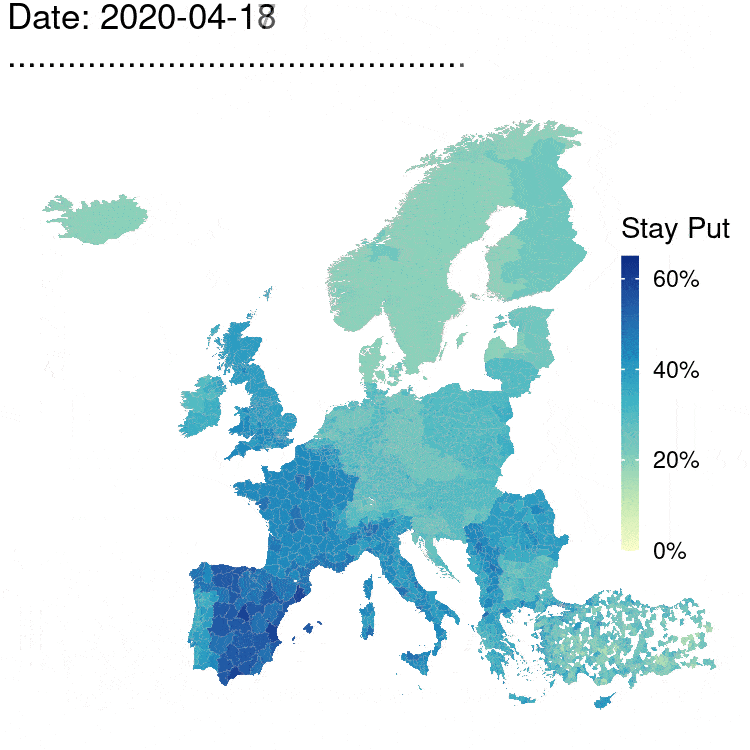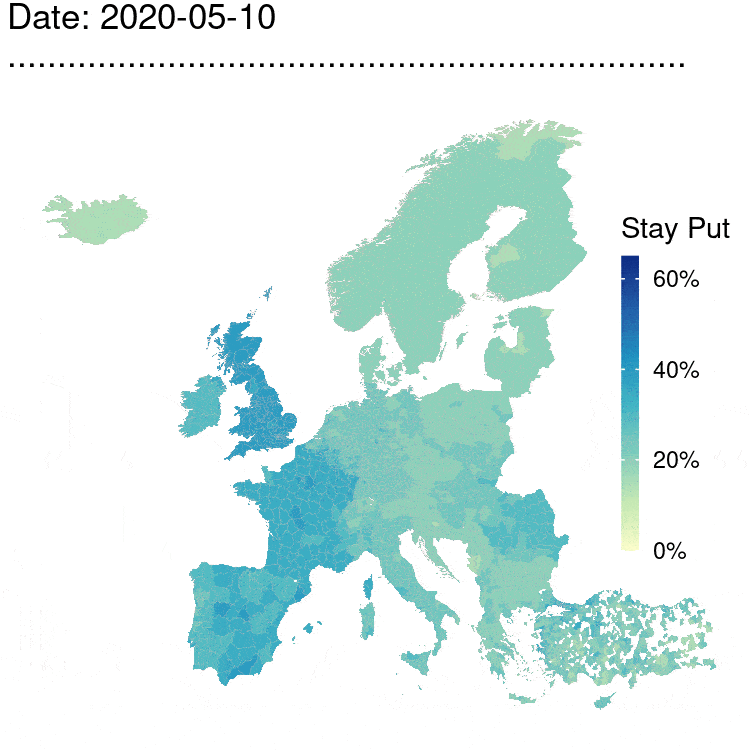
The Movement Range Maps quantify the changes in mobility of Facebook users during the COVID-19 pandemic. There are two metrics: how much their users move during each day, and how many people are generally staying at home. Each metric uses a daily value \(\varepsilon=1\), so the overall privacy budget is \(\varepsilon=2\) with user-day as a privacy unit.
Community Mobility Reports
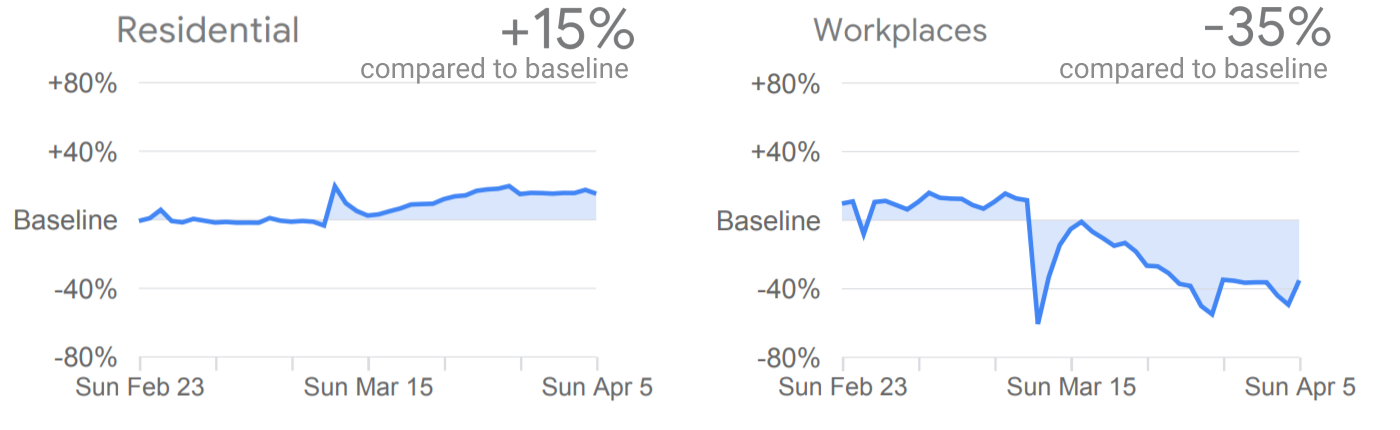
The Community Mobility Reports quantify changes in mobility patterns during the COVID-19 pandemic: how many people went to their workplace or to specific kinds of public places, and how long people spent at home. Each metric uses \(\varepsilon=0.44\) per day, and each user contributes to at most six metrics per day. Thus, the total privacy budget is \(\varepsilon=2.64\), with user-day as a privacy unit. The data was made differentially private using GoogleDP1.
Environmental Insights Explorer
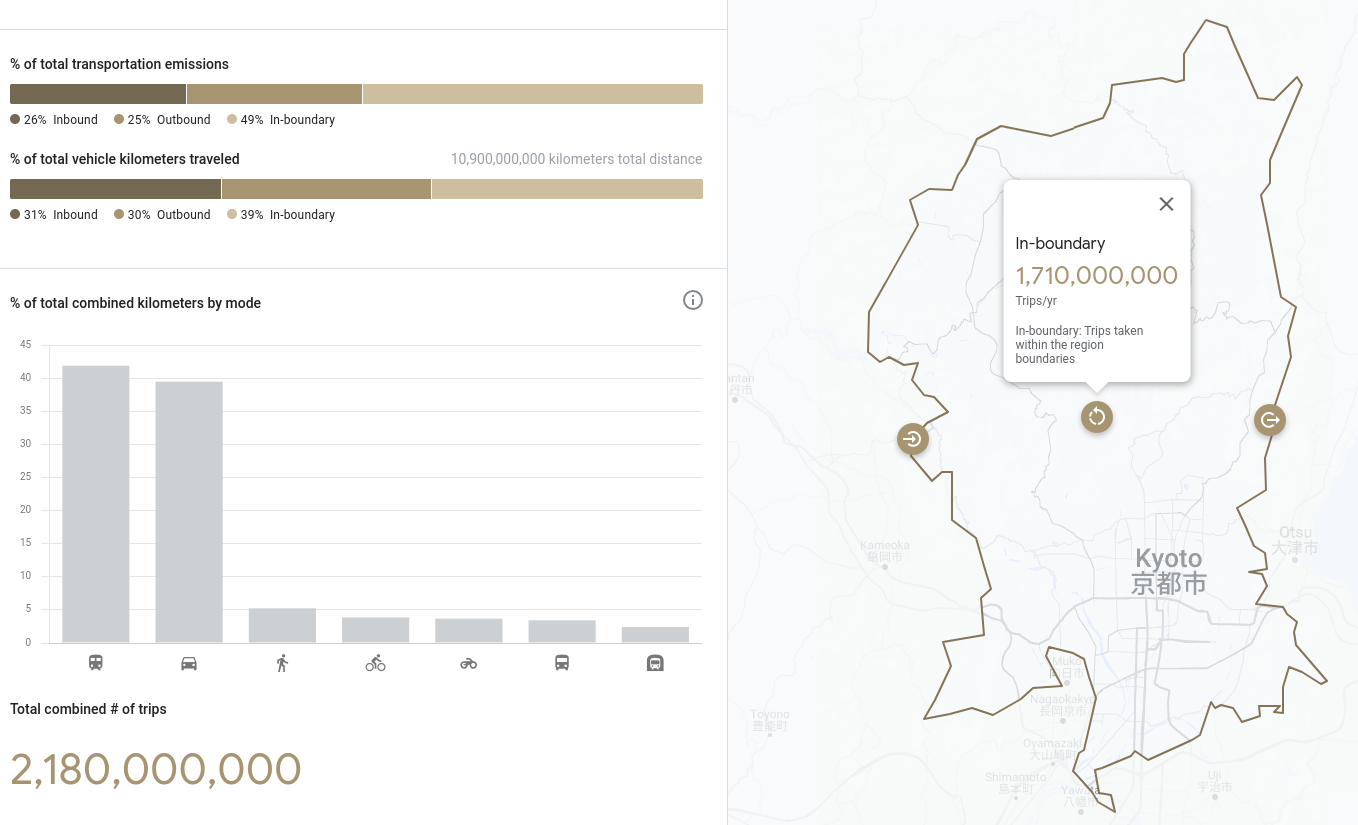
Environmental Insights Explorer reports aggregate statistics about human mobility, sliced by mode of transportation. It uses \(\varepsilon\)-DP with \(\varepsilon=2\), with a privacy unit of user-week.
Gboard next-word prediction models
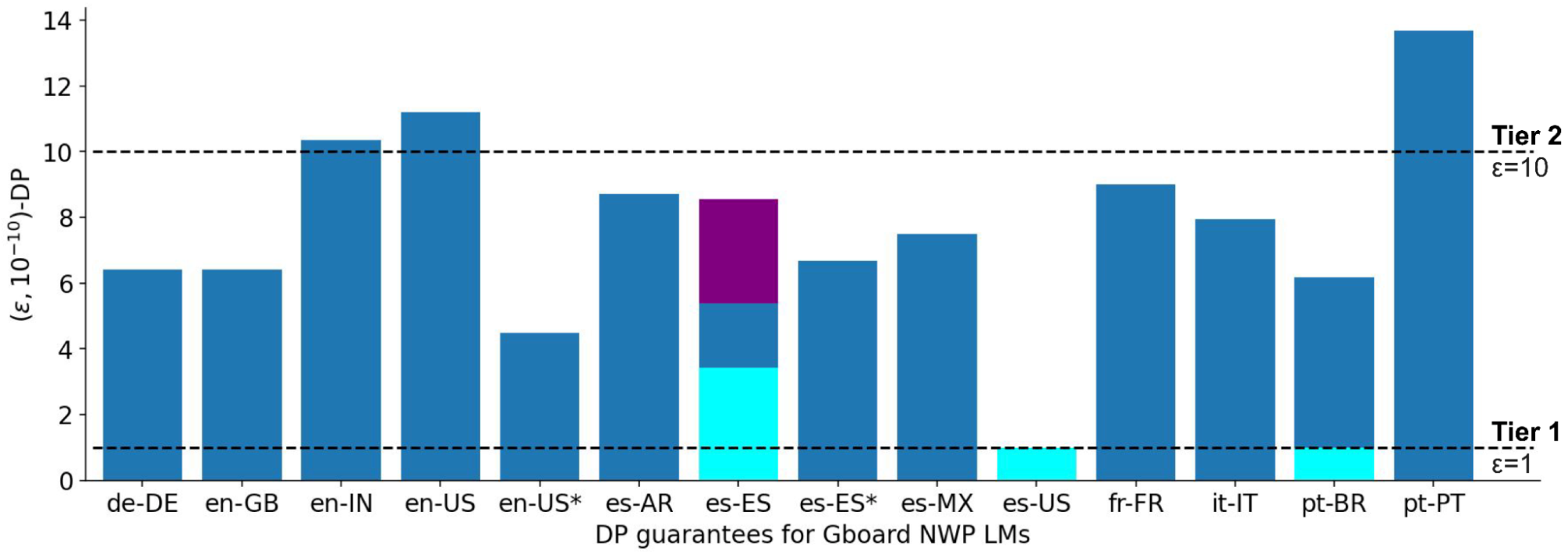
Google uses federated learning along with DP to build next-word prediction models for Gboard, a virtual keyboard application for Android. Each model uses \((\varepsilon,\delta)\)-DP with \(\delta=10^{-5}\) and \(\varepsilon\) varying between \(0.69\) and \(10.61\) depending on language. They were trained using TensorFlow Federated and TensorFlow Privacy.
Gboard out-of-vocabulary word discovery
Google uses distributed DP to discover new words to add to vocabulary lists on Gboard, a virtual keyboard application for Android. They collect data using \(\varepsilon\)-DP with \(\varepsilon=10\) in the local model, which corresponds to a central \((\varepsilon,\delta)\)-DP guarantee of \(\varepsilon=0.32\) and \(\delta=10^{-10}\). The privacy unit is a single word; each user contributes at most 60 words in 60 days.
Search Trends Symptoms Dataset
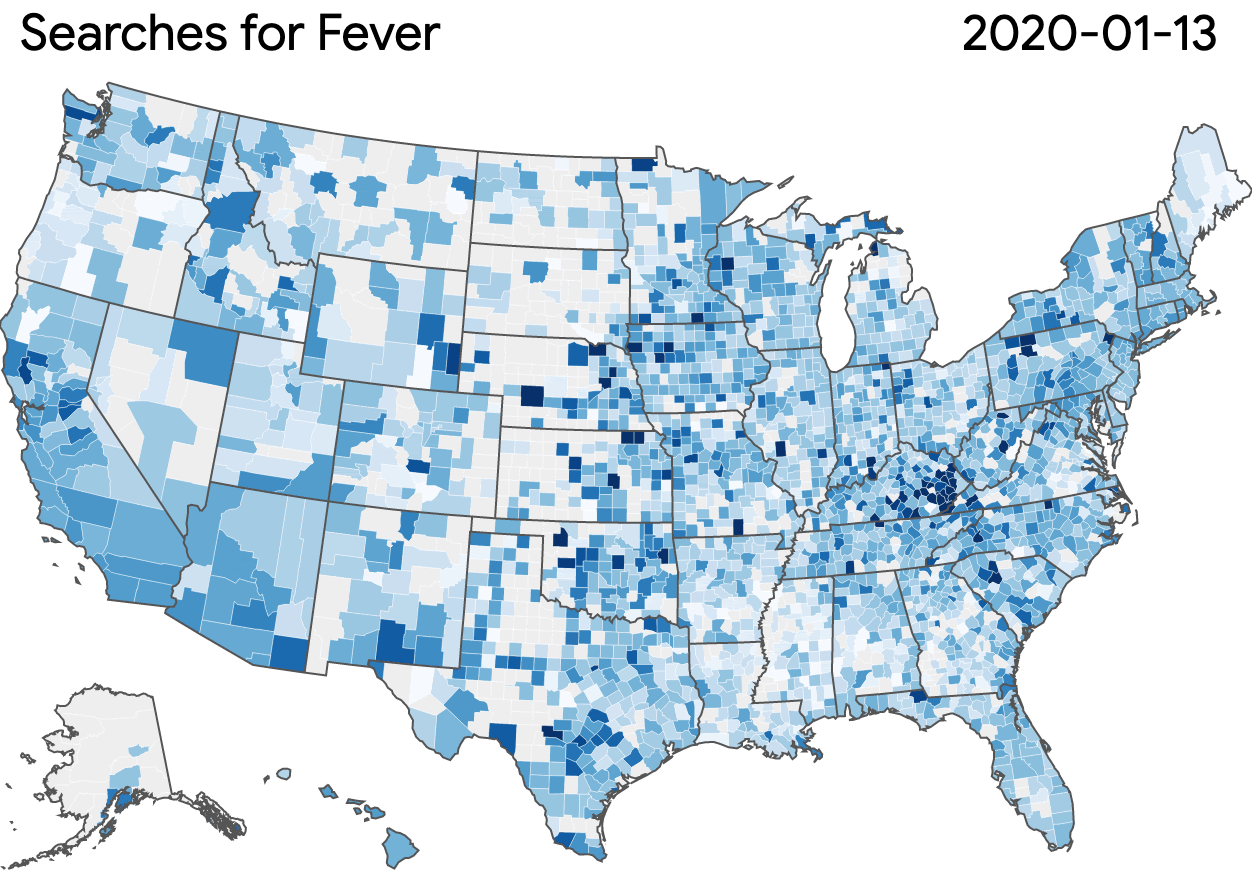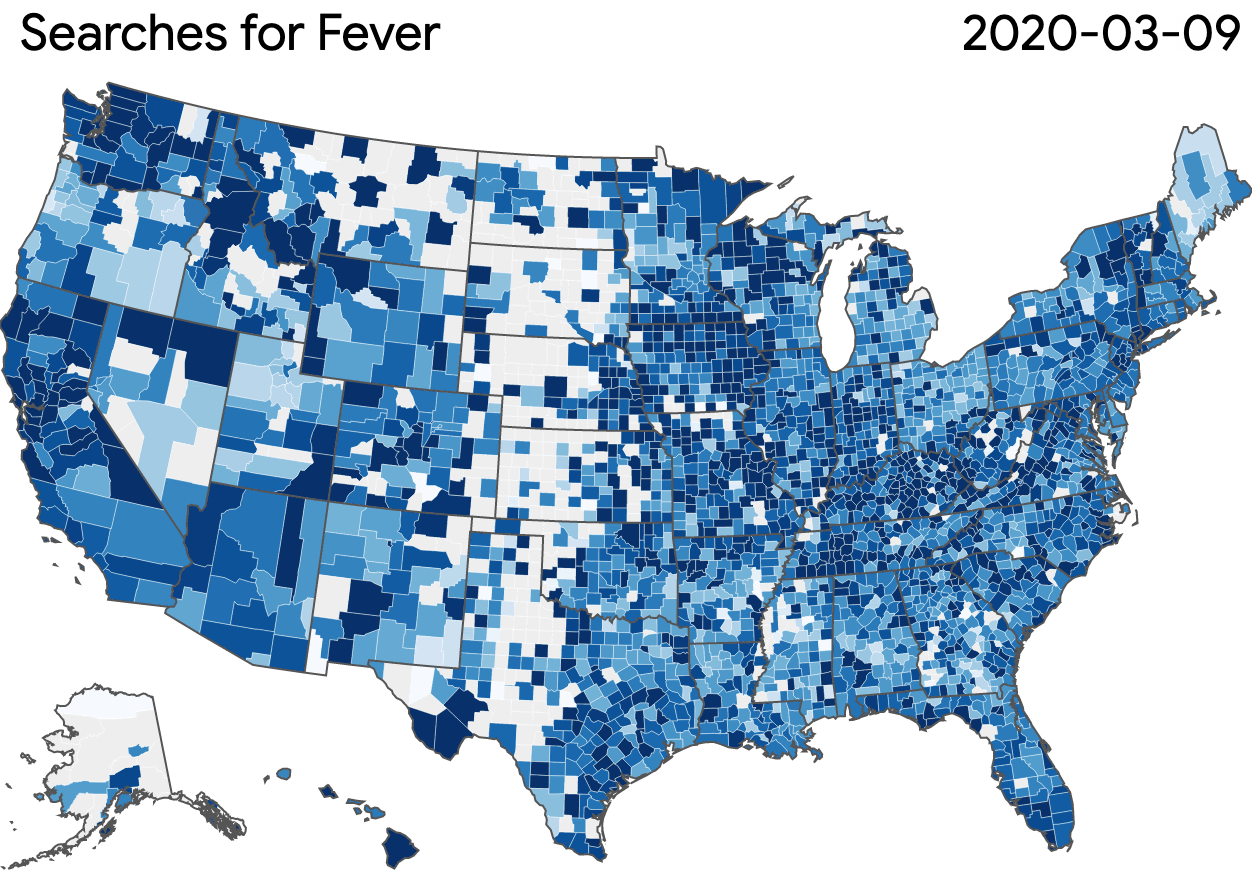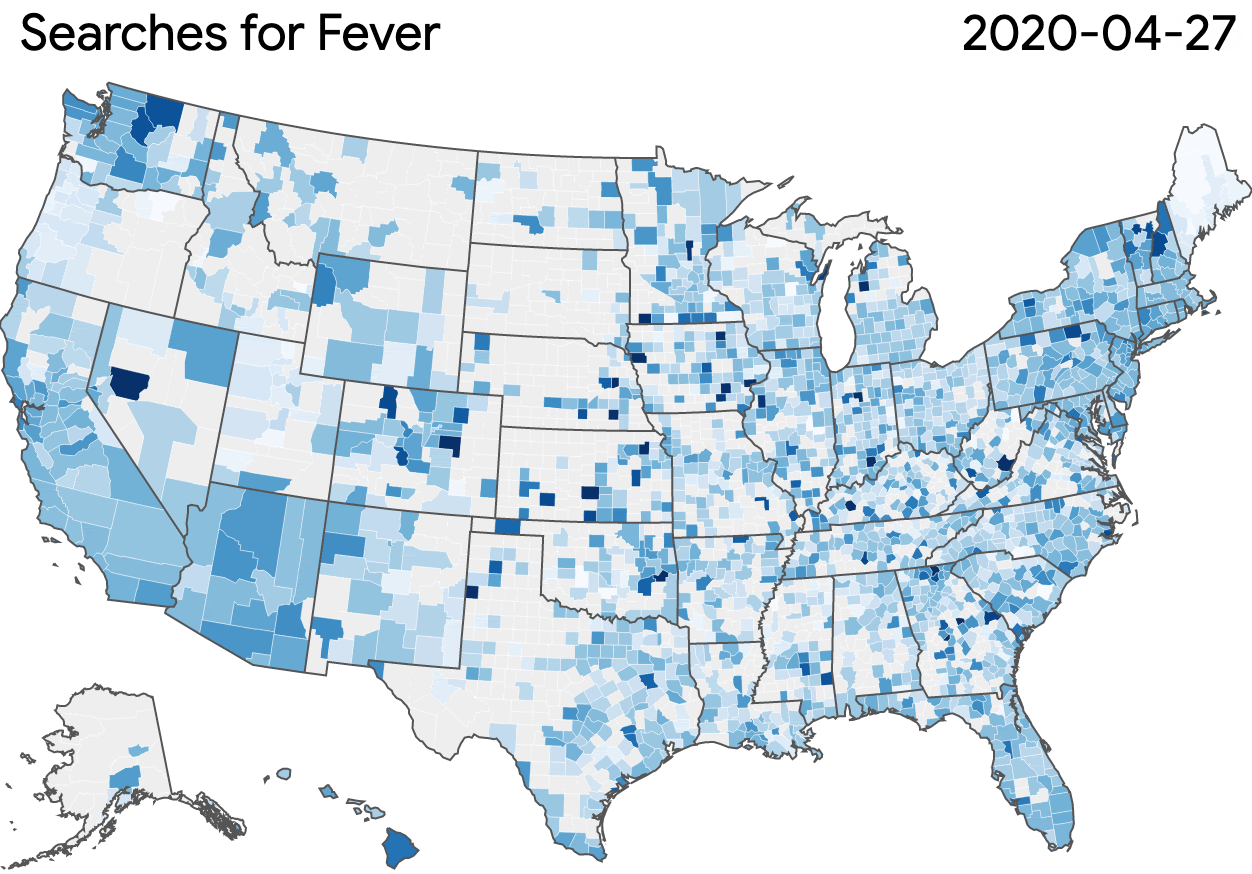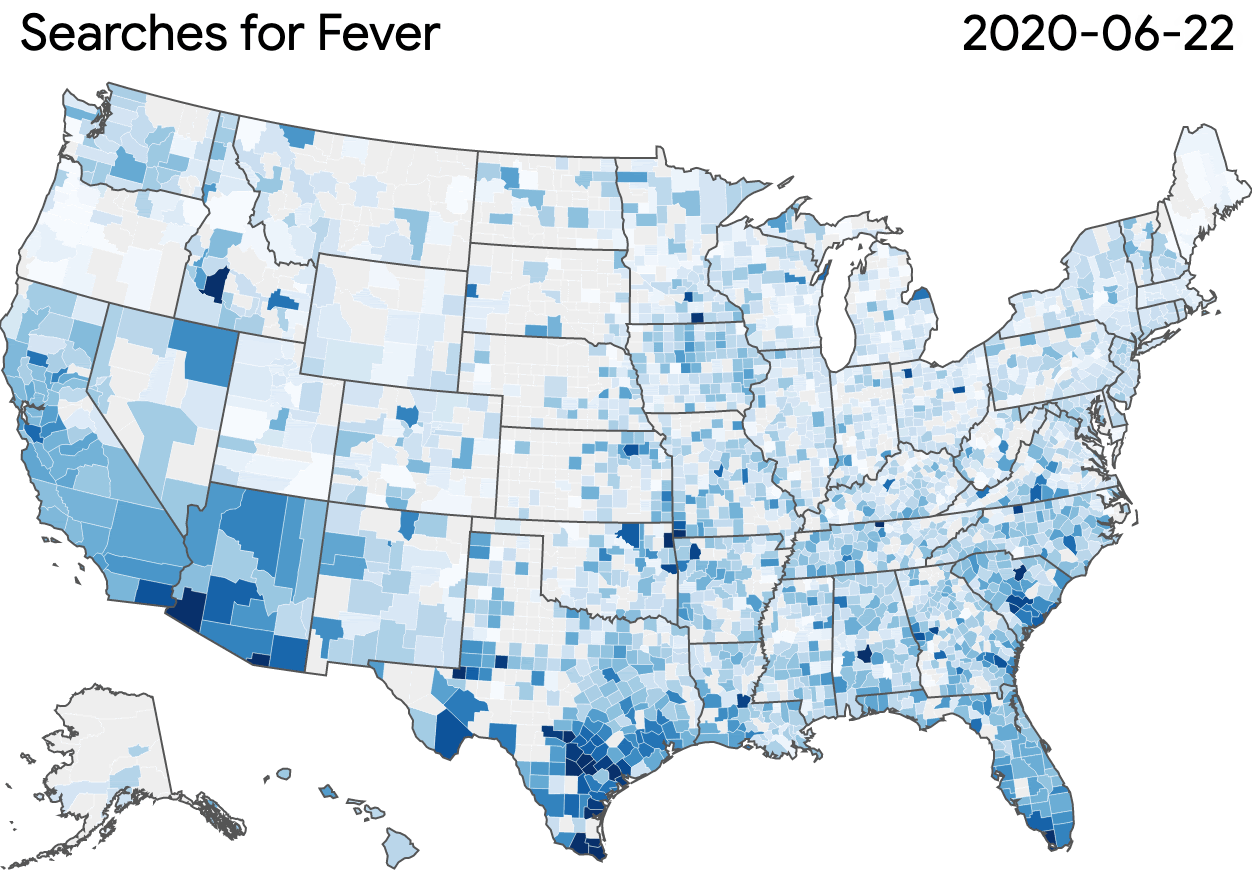
The Search Trends Symptoms Dataset measures the volume of Google searches related to a variety of symptoms. It uses \(\varepsilon=1.68\), with a user-day privacy unit; the release was generated using GoogleDP.
Shopping
Google Shopping uses a differentially private count of product page views as a signal to priorize the crawling of pages. It uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=1\) and \(\delta=10^{-9}\), with user-day as a privacy unit. The data is generated in a streaming fashion by a proprietary engine called DP-SQLP.
Trends
Google Trends uses differential privacy to select which gueries to proactively show on the website, e.g. as trending or related queries. It uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=2\) and \(\delta=10^{-10}\), with user-query as a privacy unit. The data is generated in a streaming fashion using DP-SQLP.
Urban mobility data
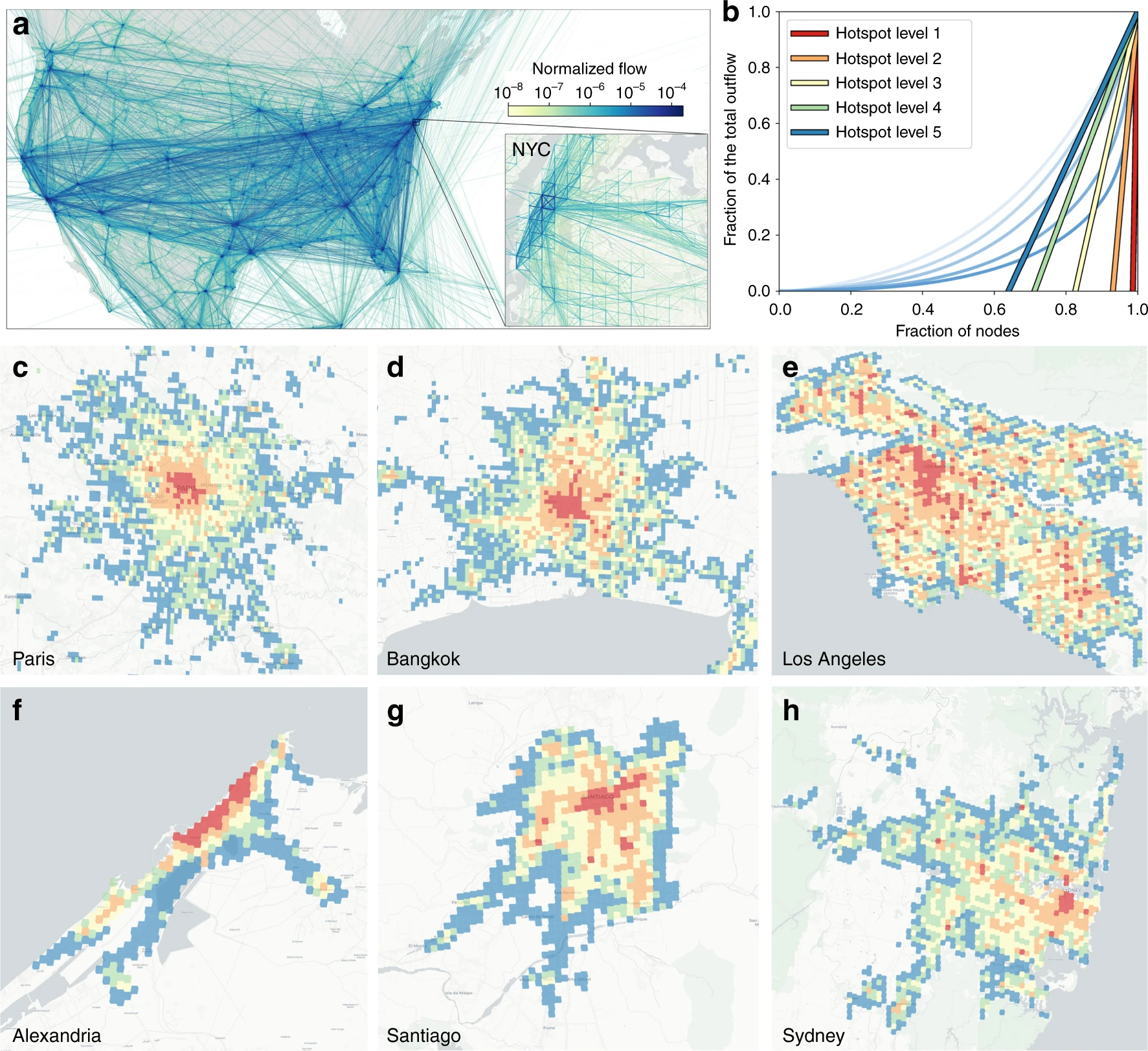
Google shared mobility data with researchers, using DP to anonymize it. The resulting paper says that this data sharing scheme used \((\varepsilon,\delta)\)-DP with \(\varepsilon=0.66\) and \(\delta=2.1\cdot10^{-29}\). The privacy unit is whether a given user made a trip from one location to another location during one week; both locations being fixed areas of size \(\approx1.3\)km².
Vaccination Search Insights
The Vaccination Search Insights quantify trends in Google searches related to COVID-19 vaccination. It uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=2.19\) and \(\delta=10^{-5}\), with user-day as a privacy unit; the data was generated using GoogleDP.
Israel's Ministry of Health
Israel's Ministry of Health published a synthetic dataset of live births in 2014 in Israel (there is also an unofficial English version), using \(\varepsilon\)-DP with \(\varepsilon=9.98\), with singleton births (with a single baby) as the privacy unit. It used custom code which reused parts of OpenDP SmartNoise and Diffprivlib, patching some vulnerabilities along the way. The data release is documented in a thorough technical paper.
Audience Engagements API
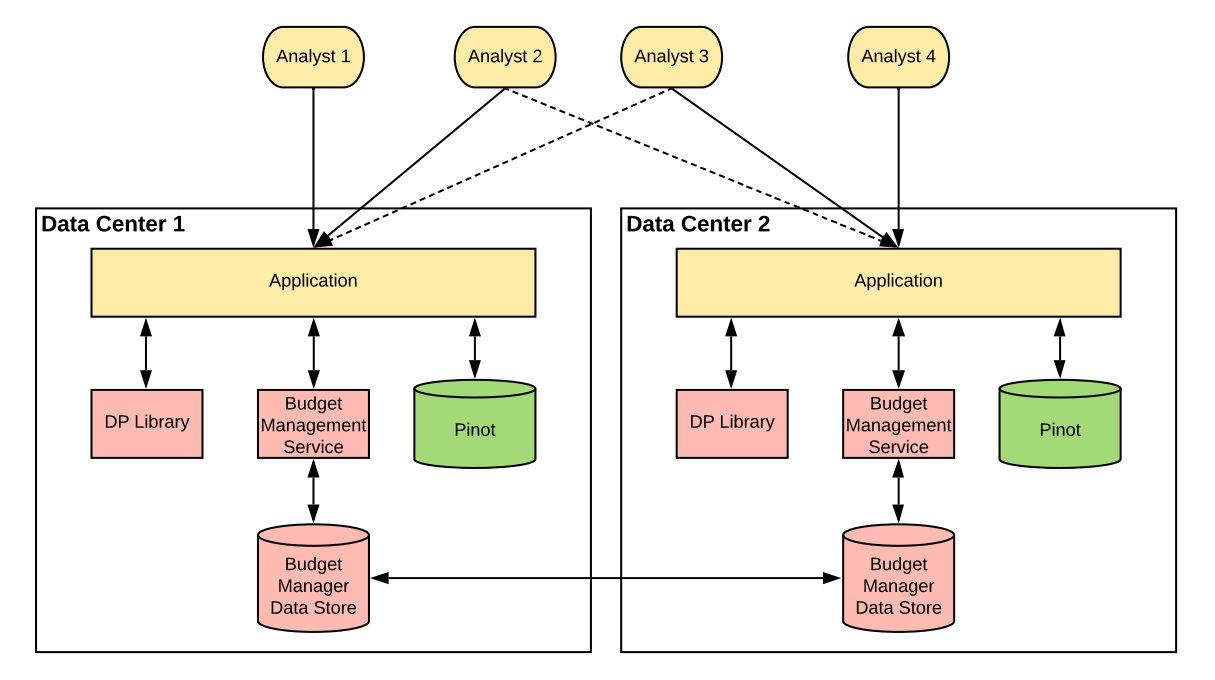
The Audience Engagements API is the only interactive query system in this list. It allows marketers to get information about LinkedIn users engaging with their content. Each query returns \((\varepsilon,\delta)\)-DP with \(\varepsilon=0.15\) and \(\delta=10^{-10}\), with a user as a privacy unit. Each analyst can send multiple queries, but a monthly cap limits how many: the total \((\varepsilon,\delta)\) budget is \(\varepsilon=34.9\) and \(\delta=7\cdot10^{-9}\), with a privacy unit of user-month-analyst.
Labor Market Insights
The Labor Market Insights measure trends in people changing their occupation on LinkedIn. There are three types of reports.
- Who is hiring? lists the companies who are hiring most. It uses \((\varepsilon,\delta)\)-DP to protect each hiring event (a LinkedIn user changing their occupation), with \(\varepsilon=14.4\) and \(\delta=1.2\cdot10^{-9}\).
- What jobs are available? enumerates the job titles that most people are being hired for. It also uses \((\varepsilon,\delta)\)-DP to protect each hiring event, with \(\varepsilon=14.4\) and \(\delta=1.2\cdot10^{-9}\).
- What skills are needed? lists the most popular skills for the jobs above. It protects each LinkedIn user's skills information during a single month with \(\varepsilon=0.3\) and \(\delta=3\cdot10^{-10}\).
This suggests a total \(\varepsilon=28.8\) and \(\delta=2.4\cdot10^{-9}\)-DP for hiring events, and \(\varepsilon=0.3\) and \(\delta=3\cdot10^{-10}\) for skill information during a single month. However, there are many subtleties involved in the above analysis. It's very possible to interpret the paper differently.
Race/ethnicity estimation
LinkedIn uses differential privacy as part of a system that estimates the race and ethnicity of users and help measure algorithmic bias of various AI features. It uses \(\varepsilon\)-DP with \(\varepsilon=4.5\), with a user as a privacy unit.
Microsoft
Global victim-perpetrator synthetic dataset
Microsoft collaborated with the International Organization for Migration to publish the Global Victim-Perpetrator Synthetic Dataset, which provides information about victims and perpetrators of trafficking. The release uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=12\) and \(\delta=5.8\cdot10^{-6}\); the privacy unit is a victim in the original dataset. It uses custom code to generate the data.
Telemetry collection in Windows
Microsoft collects telemetry data in Windows. The process used to get information about how much time users spend using particular apps uses local DP, with \(\varepsilon=1.672\), and a privacy unit of user-6-hours.
U.S. Broadband Coverage Dataset
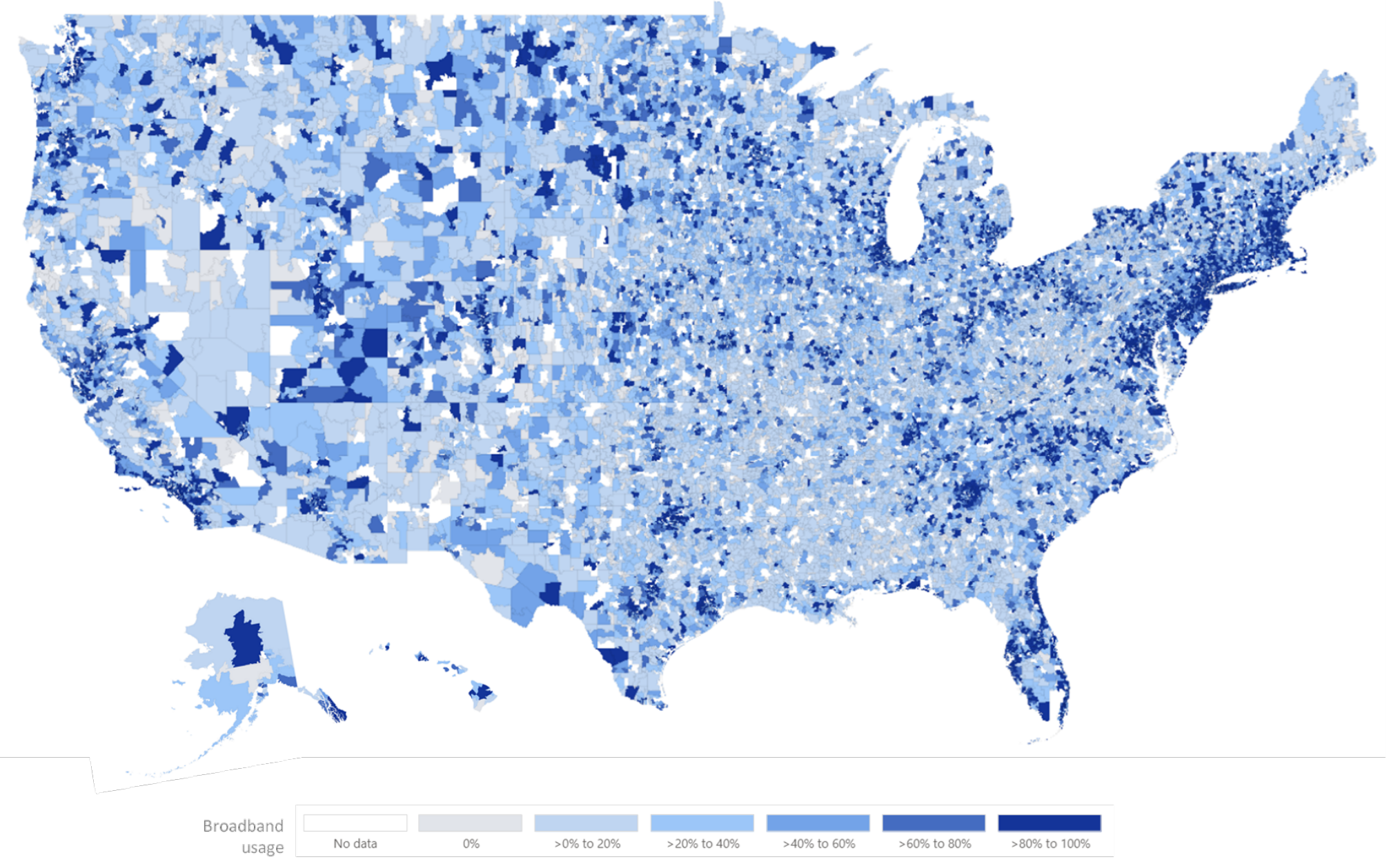
The U.S. Broadband Coverage Dataset quantifies the percentage of users having access to high-speed Internet across the US. It uses \(\varepsilon\)-DP with \(\varepsilon=0.2\), the privacy unit is a user. The data was privatized using OpenDP SmartNoise.
OhmConnect
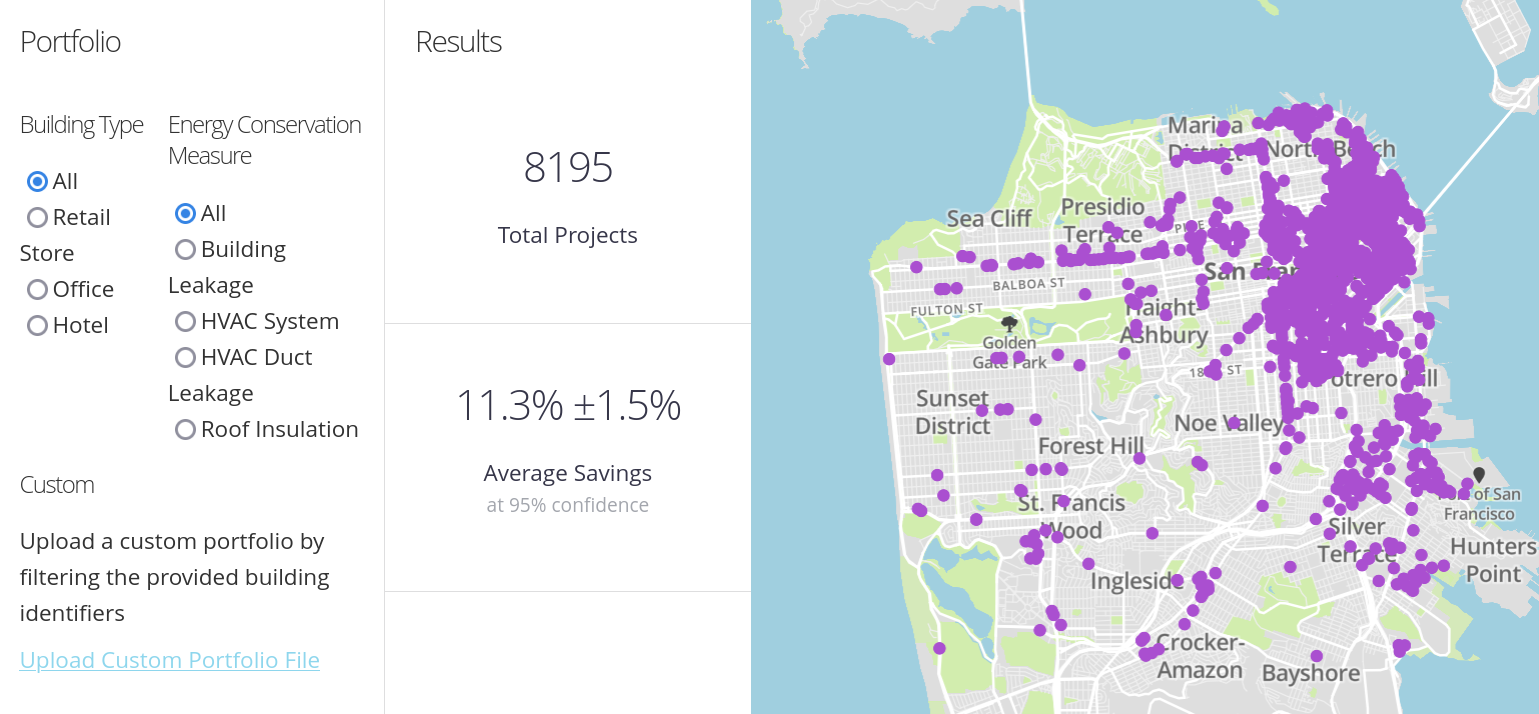
The Energy Differential Privacy project enables sharing of smart meter data. In one project, Recurve helped OhmConnect share data from their virtual power plant. This project uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=4.72\) and \(\delta=5.06\cdot10^{-9}\), with user as a privacy unit. The project uses both custom open-source code and Google's open-source DP libraries.
United States Census Bureau
County Business Patterns
The U.S. Census Bureau published demonstration tables for their County Business Patterns data product, providing information about business establishments in the US. It uses a variant of differential privacy that provides different guarantees to businesses depending on their size. For example, a business whose annual payroll is $100,000, whose first quarter payroll is $25,000, and who has 4 employees would be protected with \((\varepsilon,\delta)\)-DP with \(\varepsilon=34.92\) and \(\delta=10^{-5}\). The project was deployed in partnership with Tumult Labs, using Tumult Analytics.
2020 Decennial Census
The 2020 Census is a series of data releases containing demographic information about the U.S. population. Each of them is protected with \((\varepsilon,\delta)\)-DP with \(\delta=10^{-5}\), and the privacy unit is a person in the dataset.
- The Redistricting Data is used as part of the legislative process. It uses \(\varepsilon=13.64\), and is implemented using custom code.
- The Demographic Housing and Characteristics File (DHC) provides demographic information tabulated by geography. It is split in two parts: "Person tables" (DHCP, counting people) use \(\varepsilon=19.46\), and "Unit tables" (DHCH, counting households) use \(\varepsilon=25.87\). Both use custom code.
- The Detailed DHC-A provides tabulations of people along more fine-grained racial and ethnic groups. It uses \(\varepsilon=49.21\), and is implemented with Tumult Analytics.
- The Detailed DHC-B provides household tabulations along fine-grained racial and ethnic groups. It uses \(\varepsilon=45.68\), and is implemented with Tumult Analytics.
- The Supplemental DHC combines characteristics of households and the people living in them. It uses \(\varepsilon=12.74\), and is implemented with Tumult Analytics.
These data releases are generated in two steps: first, the algorithm computes DP statistics by adding noise to aggregations, then it performs complex post-processing steps to improve the utility of the data. The U.S. Census Bureau also publishes noisy measurement files for the Redistricting Data and the Demographic Housing and Characteristics File: this is the DP output of the first stage, without any post-processing. Since this is from the same run as the data releases above, the privacy budget is not affected by these additional publications.
OnTheMap
OnTheMap was the first-ever real-world deployment of DP. It provides statistics on where US workers are employed and where they live. This data release uses \((\varepsilon,\delta)\)-DP with \(\varepsilon=8.6\) and \(\delta=10^{-5}\), the privacy unit is a person in the dataset, and the methods are described in details in this paper2.
Post-Secondary Employment Outcomes
The Post-Secondary Employment Outcomes provide data about the earning and employment of college graduates. The technical documentation mentions two statistics using \(\varepsilon\)-DP with \(\varepsilon=1.5\), for a total privacy budget of \(\varepsilon=3\). The privacy unit is a person in the dataset, and the methods are described in detail in this paper.
Wikimedia Foundation
Page view statistics
The Wikimedia Foundation, helped by Tumult Labs, published statistics about how many distinct users visited each Wikipedia page on each day, from each country. The data publication also covers other Wikimedia projects, and is split in three parts.
- Data from July 1st, 2015 to February 8th, 2017 is protected with \(\varepsilon\)-DP with \(\varepsilon=1\), the privacy unit being 300 page views per day.
- Data from February 9th, 2017 to February 5th, 2023 is protected with \(\varepsilon\)-DP with \(\varepsilon=1\), the privacy unit being 30 page views per day.
- Data from February 6th, 2023 onwards is protected with \((\varepsilon,\delta)\)-DP with \(\varepsilon=0.72\) and \(\delta=10^{-5}\), with a user-day privacy unit.
The data publication uses Tumult Analytics. A technical paper explains the why different privacy units and privacy budgets are used for different periods.
Editor statistics
The Wikimedia Foundation, helped by Tumult Labs, publishes statistics about editor activity by project and country, on Wikipedia and other Wikimedia projects. The data publication happens at two separate time intervals.
- Some data is published monthly, and uses \(\varepsilon\)-DP with \(\varepsilon=2\) and a privacy unit of editor-project-country-month.
- Some data is published weekly, and also uses \(\varepsilon\)-DP with \(\varepsilon=2\) and a privacy unit of editor-project-country-week.
- A one-off release for Russian editors used \(\varepsilon\)-DP with \(\varepsilon=0.1\) and a privacy unit of editor-project-country-month.
These datasets are generated using Tumult Analytics.
Other deployments
This list is almost certainly incomplete. Again, don't hesitate to reach out if you'd like me to add or correct something!
- Apple uses differential privacy to learn iconic scenes scenes and improve key photo selection for the Memories and Places iOS apps. The blog post mentions using \((\varepsilon,\delta)\)-DP with \(\varepsilon=1\) and \(\delta=1.5\cdot10^{-7}\), but the privacy unit is not specified.
- Apple and Google's Exposure Notification framework has an analytics component that uses distributed DP. The paper mentions a local \(\varepsilon=8\) and corresponding central values of \(\varepsilon\) depending on how many users participate and on the central \(\delta\) chosen. However, it does not specify the privacy unit, the number of aggregations, nor the minimal number of participating users.
- Brave uses differential privacy to collect usage analytics using distributed DP. The implementation is public so the privacy parameters could in principle be figured out, but there are not summarized anywhere, and are likely evolving over time.
- Google mentions using DP in two Google Maps features: the first quantifies how busy public places are during the day, the second which restaurant's dishes are most popular. It does not specify the privacy parameters used nor the exact method used to generate the data.
- Google's RAPPOR used to collect browsing information in Google Chrome with local DP. It is now deprecated.
- Google mentions using DP and federated learning to train models to improve text selection and copying on Android. The deployment uses distributed DP, which provides similar guarantees to local DP, with additional assumptions about the adversary (which must be honest-but-curious). The value of \(\varepsilon\) is reported to be "in the hundreds", but not precisely specified; the privacy unit is also not reported.
- Google mentions training a safety classifier using DP synthetic data; the classifier is then used on mobile devices to control the output of a large language model. Privacy parameters are not reported.
- LinkedIn mentions using DP for post analytics. The value of \(\varepsilon\) is reported to be "in the hundreds", but not precisely specified; the privacy unit is also not reported.
- The Internal Revenue Service and the U.S. Department of Education, helped by Tumult Labs, used DP to publish college graduate income summaries. The data was generated using Tumult Analytics and published on the College Scorecard website. The project is outlined in this post, but no specific privacy parameters are given.
- Microsoft's Assistive AI automatically suggests replies to messages in
Office tools. It provides \((\varepsilon,\delta)\)-DP with \(\varepsilon=4\) and
\(\delta<10^{-7}\), but does not specify what the privacy unit is.
- A separate blog post by Microsoft suggests that this choice of \(\varepsilon=4\) is a policy standard across use cases for differentially private machine learning, and applies to the data of each user over a period of 6 months.
- Microsoft also mentions using DP in Workplace Analytics: this allows managers to see data about their team's interactions with workplace tools. No specific information about privacy parameters is given.
- Spectus published a dashboard containing DP metrics about mobility trends during Hurricane Irma, and the page suggests that they generated similar datasets for other natural disasters. The whitepaper mentions that OpenDP SmartNoise was used to generate four \(\varepsilon\)-DP metrics for a total \(\varepsilon=10\); the privacy unit is not specified.
- The U.S. Census Bureau publishes the Gridded Environmental Impact Frame, a dataset combining demographic data and exposure data for environmental hazards. It is protected with a noise infusion process heavily inspired by differential privacy, but some design choices mean that the release does not have formal privacy guarantees.
- The U.S. Census Bureau publishes the Opportunity Atlas, a dataset about economic mobility. The technical description mentions that the dataset is protected with \(\varepsilon\)-DP with \(\varepsilon=8\), but also mentions adding normally distributed noise to statistics; this suggests a non-zero \(\delta\) value, but no such value is reported.
- The U.S. Census Bureau publishes the Veteran Employment Outcomes, a dataset about labor market outcomes for discharged veterans. The technical description has details about the mechanisms used and suggests that the privacy unit is an individual in the data, but the numeric privacy parameters are not reported.
There are (many) other examples of companies and organizations saying they use DP. I only added them here if they point to a specific project or feature.
Finally, many scientific papers report experimental results on real datasets. Most don't mention whether the system was deployed. I did not attempt to list those.
Caveats & comments
Comparing projects
You should not use this list to make broad statements or comparisons about the privacy posture of different organizations. Differential privacy parameters are a very small part of the story, even for these specific projects. How was the data collected? How long is it kept? How sensitive is it? Who has access to the input and output data? Answering these questions is crucial to put each DP deployment and its parameters in context.
In addition, different privacy units also make simple comparisons fairly meaningless. Even across time periods, the semantics are subtle. As an example, consider two DP processes.
- Process \(A\) uses a privacy unit of user-day with \(\varepsilon_A=0.2\).
- Process \(B\) uses a privacy unit of user-month with \(\varepsilon_B=3\).
Can we simply multiply \(\varepsilon_A\) by \(30\) to compare it to \(\varepsilon_B\)? Well, not really. The data of a user during a single day is protected by Process \(A\) with \(\varepsilon_A\), which is better than what Process \(B\) can guarantee (at most \(\varepsilon_B\)). But with process \(A\), the data of an entire month is only protected with \(30\varepsilon_A=6\) with Process \(A\), so Process \(B\) has better guarantees. And this is without the possibility of using better privacy accounting methods, to get tighter parameters for the monthly guarantees of Process \(A\).
What's a user?
Many of these projects have user as part of their privacy unit. This can mean slightly different things depending on the project: a device (for telemetry collection), an account (for online services), a household (for smart meter data), and so on. This means that an individual who uses multiple devices or accounts on the same online service might get weaker privacy guarantees. This subtlety is not always made explicit.
Replacement vs. addition/removal
In differential privacy, the definition of the two neighboring datasets can be of two types. Do you change the data of one person? Or do you add or remove a user? This subtlety is also not always explicit, and I've ignored it in the list above.
Zero-concentrated differential privacy
Multiple data releases use zero-concentrated DP to do the privacy budget accounting. Some report guarantees using this definition, others convert the guarantees to \((\varepsilon, \delta)\)-DP in communication materials. To make the comparison easier, I converted all these guarantees to \((\varepsilon,\delta)\)-DP with \(\delta=10^{-5}\); even when the reported \(\delta\) is different.
Number precision
I rounded all the numbers to the second decimal point. Most of the equal signs should be understood to be \(\approx\) signs instead.
Thanks to Anthony Caruso, Ashwin Machanavajjhala, Erik Taubenek, Hal Triedman, John Abowd, Kai Yao, Lars Vilhuber, Lorraine Wong, Marc Paré, Osonde Ope Osoba, Peter Kairouz, Philip Leclerc, Rodrigo Racanicci, Sergey Yekhanin, Tancrède Lepoint, and Ziteng Sun for their helpful comments and suggestions.
-
The project name in the GitHub repository is "Google's differential privacy libraries"; most of the academic literature uses "GoogleDP" to refer to it, so I reuse the abbreviation here. ↩
-
John Abowd confirmed in personal correspondence that the parameters mentioned in the paper are the ones used for the actual deployment. ↩