

Paper highlight: Evaluations of Machine Learning Privacy Defenses are Misleading
Here's an idea: why don't I use this blog to highlight cool privacy papers with interesting insights? Let's try this out. We'll see if it becomes a more regular thing.
Machine learning models tend to memorize their training data. That's a problem if they're trained on sensitive information, and then pushed to production: someone could interact with them and retrieve exact, sensitive data points.
Researchers have come up with a bunch of ways to mitigate this problem. These defenses fall in two categories.
- Some techniques provide differential privacy guarantees, like DP-SGD.
- Other approaches are more ad hoc. We can't mathematically prove that they protect against all attacks, but maybe we can show that they work well enough in practice.
In both cases, it makes sense to empirically evaluate how good these defenses are in practice. For the ad hoc mitigations, it's the only way to get an idea of how well they work. For the DP methods, it can complement the mathematical guarantees, especially if the privacy budget parameters are very large. So, many papers introducting defenses dutifully run some attacks on their models, and report success rates. These numbers typically look pretty good, which allows the authors to say that their new mitigation is solid.
That all sounds great, until someone starts taking a closer look at how these evaluations actually work. That's exactly what Michael Aerni, Jie Zhang, and Florian Tramèr did in a new paper, titled « Evaluations of Machine Learning Privacy Defenses are Misleading ».
You can probably guess where this is going: they found that these empirical privacy evaluations are actually pretty terrible. They identify three main problems with existing work.
- Average-case privacy. Empirical privacy metrics are defined in a way that measures average risk across the dataset, instead of worst-case risk. So if the approach does a terrible job at protecting outliers data points, you can't see that in the metric. That's not great: everyone deserves privacy protection, not just typical data points!
- Weak attacks. Many evaluations only try very simple attacks. They don't use state-of-the-art techniques, and they don't adjust them depending on the mitigation. That's not great: real-world attackers are definitely going to do both!
- Bad baselines. A lot of evaluations use DP-SGD as a baseline, but they do so in a way that seems set up to make it fail. First, they don't incorporate state-of-the-art improvements to DP-SGD that improve utility. Second, they select privacy parameters that lead to very bad accuracy. That's not great: it makes newly proposed defenses compare more favorably for no good reason!
To fix all that, the authors introduce better privacy metrics, stronger attacks, and more reasonable baselines. They implement all that, and re-run a bunch of experiments from previous papers introducing new defenses. The findings are summarized in the following chart.
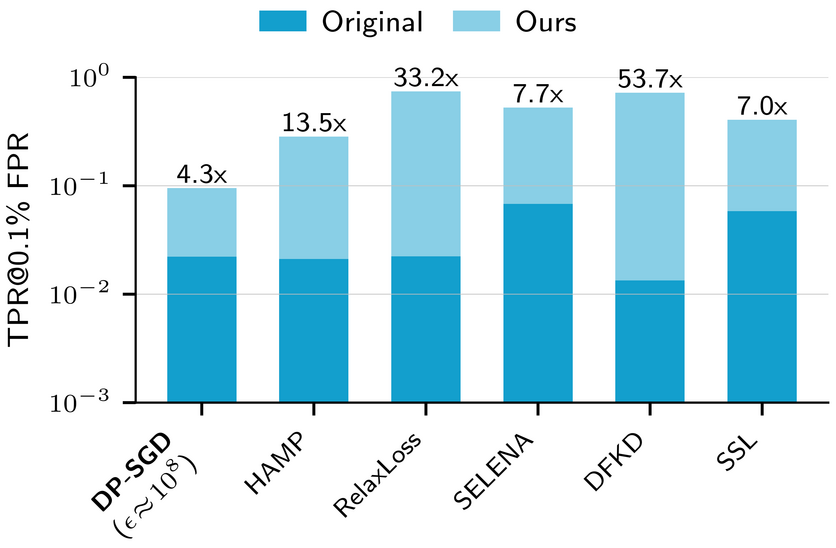
On the x-axis, a bunch of defenses; on the y-axis, a measure of attack success. In dark blue are the original numbers, in light blue are the new results. Two things are immediately apparent:
- Making attacks better lead to better success rates. This is unsurprising, but the magnitude of these improvements is kind of amazing : between 7x and 53x better! That says a lot about how brittle these attack scores are. You probably don't want to rely exclusively on empirical risk metrics for real-world use cases. When real people's privacy is at stake, someone finding a way to multiply your empirical risk by a factor of 50 overnight would be seriously bad news.
- The DP-SGD baseline, once improved to match the accuracy of other approaches, provides the best empirical risk mitigation. This somewhat surprising, since the privacy parameters used are extremely loose — an \(\varepsilon\) of \(10^8\) is completely meaningless from a mathematical standpoint. This suggests that DP techniques might still be worth using even if you don't care about formal guarantees, only about empirical risk. Super large \(\varepsilon\) values are somehow still much better than infinite ones, it seems.
I'll add one personal comment to these two takeaways. It's maybe a little too spicy to be published in a scientific paper without hard data, but this is a blog post, and who's going to stop me?
This research shows a lot about incentives at play in privacy research based on empirical metrics. I don't think the authors of the ad hoc defenses set out to do meaningless evaluations, and recommend unsafe practices. But none of them had a structural incentive to do better. Coming up with better attacks is more work, and the only possible outcome is that the proposed defenses become less convincing and harder to publish. Same for optimizing baselines, or coming up with stricter risk metrics. To make things worse, when you genuinely think that your defense is reasonable, it's really hard to switch to an adversarial mindset and try to break what you just created! Nothing pushes researchers towards better risk quantification1. So in a way, it's not very surprising that this leads to widespread underestimation of actual risk.
So, incentives are broken in academic research around these empirical privacy scores. Now, could the same broken incentives also affect other areas? Say, commercial vendors of privacy technology who rely on the same empirical metrics to claim that their products are safe and GDPR-compliant? I'll leave that as an exercise to the reader.
To come back to the paper, here's a little more praise to make you want to read it. The empirical privacy metric makes a lot more sense than most I've seen heard of so far. The attack methodology is both elegant and clever. The "name and shame" counterexample is worth keeping in mind if you design new privacy scores. The examples of the most vulnerable data points give a clear picture of what existing defenses fail to protect. Convinced yet?2 Go read it!
-
And I can't help but note that by contrast, using differential privacy keeps you honest: you have to quantify the privacy loss of everything. You're computing a worst-case bounds, and you can't cheat. Barring errors in proofs — which are easier to catch at review time than, say, subpar implementation of baselines — the number you get is the best you can do. And doing more work can only make your results stronger. ↩
-
No? Then read the paper just for the spicy fun facts. Here's my favorite: some papers used synthetic data as a defense, and, I kid you not, « argue privacy by visually comparing the synthetic data to the training data ». I couldn't come up with this if I was aiming for satire. ↩