

Differential privacy in (a bit) more detail
This post is part of a series on differential privacy. Check out the table of contents to see the other articles!
As I mentioned in the previous article, differential privacy is pretty awesome. If I did a good job, you're now wondering what the real definition looks like. So in this post, I will go into a bit more detail into what differential privacy actually means, and why it works so well. There will be some math! But I promise I will explain all the concepts I use, and give lots of intuition.
The definition
We saw that a process satisfies differential privacy if its output is basically the same if you change the data of one individual. And by "basically the same", we meant "the probabilities are close".
Let's now translate that into a formal definition.
A process \(A\) is \(\varepsilon\)-differentially private if for all databases \(D_1\) and \(D_2\) which differ in only one individual:
… and this must be true for all possible outputs \(O\). Let's unpack this.
\(\mathbb{P}\left[A(D_1)=O\right]\) is the probability that when you run the process \(A\) on the database \(D_1\), the output is \(O\). This process is probabilistic: if you run it several times, it might give you different answers. A typical process might be: "count the people with blue eyes, add some random number to this count, and return this sum". Since the random number changes every time you run the process, the results will vary.
\(e^\varepsilon\) is the exponential function applied to the parameter \(\varepsilon>0\). If \(\varepsilon\) is very close to 0, then \(e^\varepsilon\) is very close to 1, so the probabilities are very similar. The bigger \(\varepsilon\) is, the more the probabilities can differ.
Of course, the definition is symmetrical: you can replace \(D_1\) by \(D_2\) and vice-versa, and the two databases will still differ in only one individual. So we could replace it by:
Thus, this formula means that the output of the process is similar if you change or remove the data of one person. The degree of similarity depends on \(\varepsilon\): the smaller it is, the more similar the outputs are.
What does this similarity have to do with privacy? First, I'll explain this with an intuitive example. Then, I'll formalize this idea with a more generic interpretation.
A simple example: randomized response
Suppose you want to do a survey to know how many people are illegal drug users. If you naively go out and ask people whether they're using illegal drugs, many will lie to you. So you devise the following mechanism. The participants no longer directly answer the question "have you consumed illegal drugs in the past week?". Instead, each of them will flip a coin, without showing it to you.
- On heads, the participant tells the truth (Yes or No).
- On tails, they flip a second coin. If the second coin lands on heads, they answer Yes. Otherwise, they answer No.
How is this better for survey respondents? They can now answer Yes without revealing that they're doing something illegal. When someone answers Yes, you can't know their true answer for sure. They could be actually doing drugs, but they might also have answered at random.
Let's compute the probabilities of each answer for a drug user.
- With probability 50%, they will say the truth and answer Yes.
- With probability 50%, they will answer at random.
- They then have another 50% chance to answer Yes, so 25% chance in total.
- Similarly, in total, they have a 25% chance to answer No.
All in all, we get a 75% chance to answer Yes and a 25% chance to answer No. For someone who is not doing drugs, the probabilities are reversed: 25% chance to answer Yes and 75% to answer No. Using the notations from earlier:
- \(\mathbb{P}\left[A(Yes)=Yes\right] = 0.75\), \(\mathbb{P}\left[A(Yes)=No\right] = 0.25\)
- \(\mathbb{P}\left[A(No)=Yes\right] = 0.25\), \(\mathbb{P}\left[A(No)=No\right] = 0.75\)
Now, \(0.75\) is three times bigger than \(0.25\). So if we choose \(\varepsilon\) such as \(e^\varepsilon=3\) (that's \(\varepsilon\simeq1.1\)), this process is \(\varepsilon\)-differentially private. So this plausible deniability translates nicely in the language of differential privacy.
Of course, with a differentially private process like this one, you're getting some noise into your data. But if you have enough answers, with high probability, the noise will cancel itself out. Suppose you have 1000 answers in total: 400 of them are Yes and 600 are No. About 50% of all 1000 answers are random, so you can remove 250 answers from each count. In total, you get 150 Yes answers out of 500 non-random answers, so about 30% of Yes overall.
What if you want more privacy? Instead of having the participants say the truth with probability 50%, you can have them tell the truth 25% of the time. What if you want less noise instead, at the cost of less protection? Have them tell the truth 75% of the time. Finding out \(\varepsilon\) and quantifying the noise for each option is left as an exercise for the reader =)
A generalization: quantifying the attacker's knowledge
Let's forget about the previous example and consider a more generic scenario. In line with the previous article, we will describe this scenario from the attacker's perspective. We have a mechanism \(A\) which is \(\varepsilon\)-differentially private. We run it on some database \(D\), and release the output \(A(D)\) to an attacker. Then, the attacker tries to figure out whether someone (their target) is in \(D\).
Under differential privacy, the attacker can't gain a lot of information about their target. And this is true even if this attacker has a lot of knowledge about the dataset. Let's take the stronger attacker we can think of: they know all the database, except their target. This attacker has to determine which database is the real one, between two options: one with their target in it (let's call it \(D_{in}\)), the other without (\(D_{out}\))1.
So, in the attacker's model of the world, the actual database \(D\) can be either \(D_{in}\) or \(D_{out}\). They might have an initial suspicion that their target is in the database. This suspicion is represented by a probability, \(\mathbb{P}\left[D=D_{in}\right]\). This probability can be anything between \(0\) and \(1\). Say, \(0.9\) if the attacker's suspicion is strong, \(0.01\) if they think it's very unlikely, \(0.5\) if they have no idea… Similarly, their suspicion that their target is not in the dataset is also a probability, \(\mathbb{P}\left[D=D_{out}\right]\). Since there are only two options, \(\mathbb{P}\left[D=D_{out}\right]=1-\mathbb{P}\left[D=D_{in}\right]\).
Now, suppose the attacker sees that the mechanism returns output \(O\). How much information did the attacker gain? This is captured by looking at how much their suspicion changed after seeing this output. In mathematical terms, we have to compare \(\mathbb{P}\left[D=D_{in}\right]\) with the updated suspicion \(\mathbb{P}\left[D=D_{in}\mid A(D)=O\right]\). This updated suspicion is the attacker's model of the world after seeing \(O\).
With differential privacy, the updated probability is never too far from the initial suspicion. And we can quantify this phenomenon exactly. For example, with \(\varepsilon=1.1\), here is what the upper and lower bounds look like.

The black line is what happens if the attacker didn't get their suspicion updated at all. The blue lines are the lower and upper bounds on the updated suspicion: it can be anywhere between the two. We can visualize the example mentioned in the previous article: for an initial suspicion of 50%, the updated suspicion is approximately between 25% and 75%.
How do we prove that these bounds hold? We'll need a result from probability theory, and some basic arithmetic manipulation. I reproduced the proof as simply as I could, but you still don't have to read it. If you want to, click here:
What does this look like for various values of \(\varepsilon\)? We can draw a generalization of this graph with pretty colors:
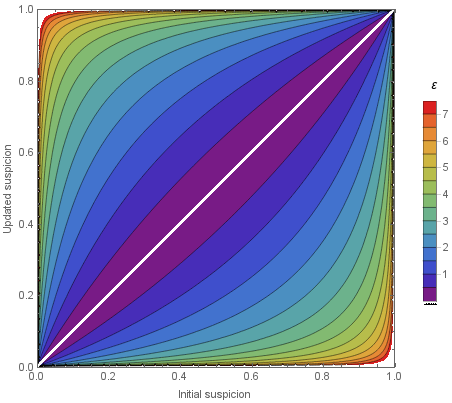
For larger values of \(\varepsilon\), this gets scary quite fast. Let's say you're using \(\varepsilon=5\). Then, an attacker can go from a small suspicion (say, 10%) to a very high degree of certainty (94%).
What about composition?
In the previous section, I formalized two claims I made in my last article. First, I explained what it means to quantify information gain. Furthermore, I picked an attacker with full background knowledge. If the attacker knows less information in the first place, the bounds we showed still hold.
What about the third claim? I said that differential privacy was composable. Suppose that two algorithms \(A\) and \(B\) are \(\varepsilon\)-differentially private. We want to prove that publishing the result of both is \(2\varepsilon\)-differentially private. Let's call \(C\) the algorithm which combines \(A\) and \(B\): \(C(D)=\left(A(D),B(D)\right)\). The output of this algorithm will be a pair of outputs: \(O=\left(O_A,O_B\right)\).
The insight is that the two algorithms are independent. They each have their own randomness, so the result of one does not impact the result of the other. This allows us to simply write:
so \(C\) is \(2\varepsilon\)-differentially private.
Future steps
I hope that I convinced you that differential privacy can be an excellent way to protect your data (if your \(\varepsilon\) is low). Now, if everything is going according to my master plan, you should be like… "This is awesome! I want to use it everywhere! How do I do that?"
I have good news for you: this blog post has sequels. Head over to the table of contents of this series to decide which one you want to read next!
Thanks to Chao Li for introducing me to the Bayesian interpretation of differential privacy, and to a3nm, Armavica, immae and p4bl0 for their helpful comments on drafts of this article (as well as previous ones).
-
This can mean that \(D_{out}\) is the same as \(D_{in}\) with one fewer user. This can also mean that \(D_{out}\) is the same as \(D_{in}\), except one user has been changed to some arbitrary other user. This distinction doesn't change anything to the reasoning, so we can simply forget about it. ↩