

A bottom-up approach to making differential privacy ubiquitous
This post is a transcript of an invited talk I delivered to PPAI-22. It was also published on the Tumult Labs website. Ashwin Machanavajjhala, Gerome Miklau, Philip Bohannon, and Sam Haney contributed to these slides.
Hi everybody! Here is a graph counting the number of academic papers related to differential privacy, over time.
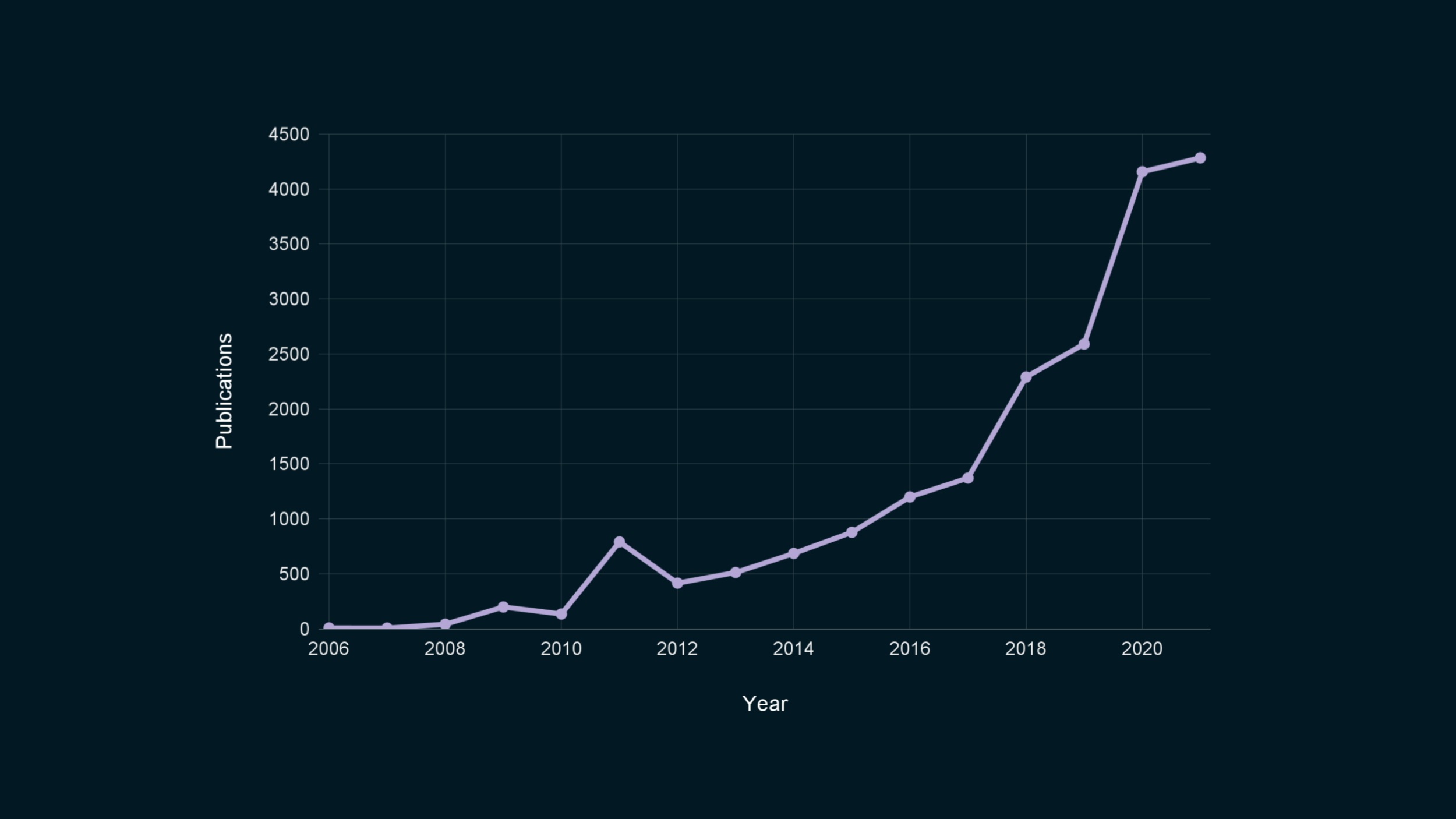
In academia, differential privacy essentially won. There is broad agreement, at least among computer scientists, that this is the notion of choice to formally bound the privacy leakage when publishing data. Differential privacy has become the default tool that people use to quantify trade-offs between privacy and accuracy.
The field is growing every year, with exciting new domains of application, empirical improvements, and theoretical advances.
For comparison, here is a graph showing the number of real-world deployments that I could find public information about.
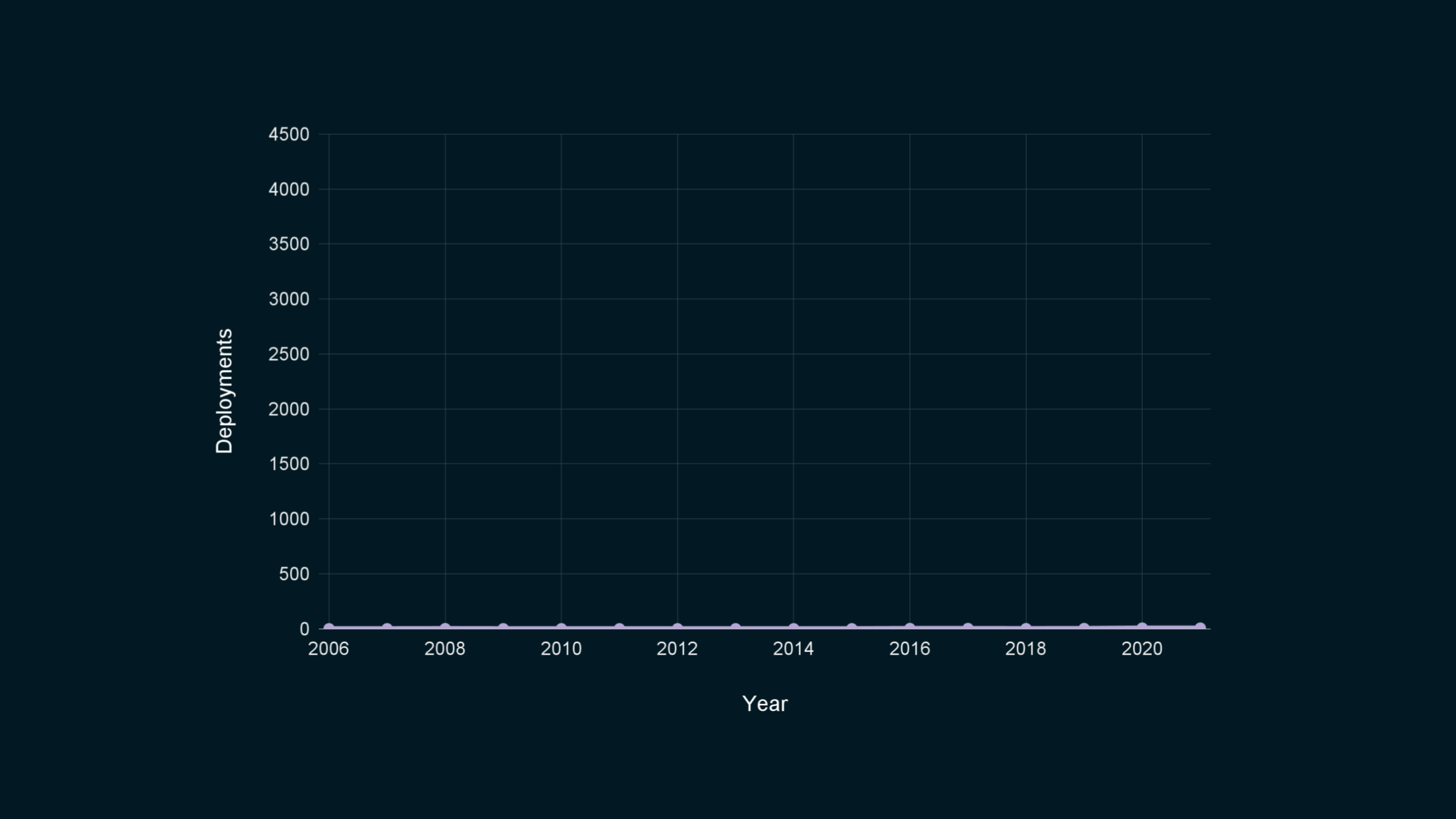
As you can see… Ooops! Sorry. I forgot to change the scale of the vertical axis.
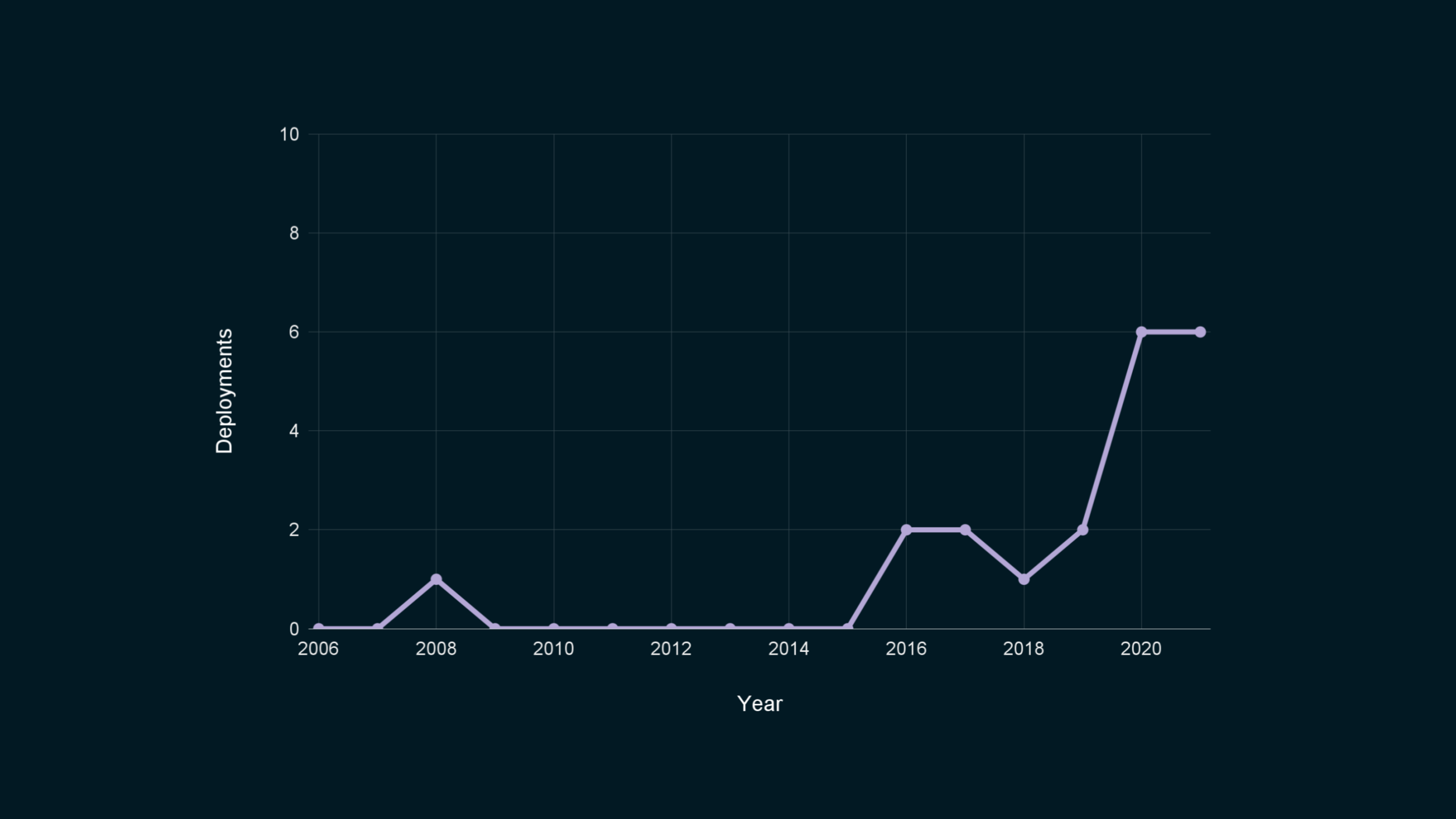
OK, now we’re seeing something… It’s not much, though. We’re still at a stage where I can list all public deployments of differential privacy in a single blog post.
I know what you’re going to say, though. There might not be many use cases, but some of these are really big.

The 2020 Decennial Census! Mobility data from around the globe to help combat COVID-19! Telemetry collection from billions of devices!
If we look at who is deploying DP, one thing in common for almost all of these organizations is that they’re large. They can afford to invest in, or contract with, specialized science and engineering teams to help them roll out this technology.
Special mention to OhmConnect, the only exception I could find to this rule! They’re a startup sharing smart meter data to increase power grid reliability.
But the problem that differential privacy solves isn’t limited to these massively large organizations: smaller organizations also have data sharing and publishing needs! Everyone could benefit from using strong anonymization techniques, not just these giants.
This is the question I’m here to talk about today. How do we bridge that gap? How do we make differential privacy ubiquitous?

I’m Damien, and I work as a scientist for Tumult Labs. We’re a startup trying to make widespread adoption of differential privacy into a reality.
In this presentation, I’ll outline a bottom-up approach for reaching that goal.
What do I mean by “bottom-up”? Well, first, here’s what a “top-down” approach could look like.

- First, we lobby decision-makers: we convince executives, regulators, standard committees, etc., that differential privacy should be the notion of choice for anonymizing data.
- Then, once DP has become a requirement in different places, like standards, regulations, internal best practices, etc.…
- People adopt it because they have to.
This comes with many challenges.
- First, writing good policy documents and guidance is very difficult. We would need to answer questions like “how to choose parameters”, which are already tricky for specific use cases, but even harder to decide on in generic terms.
- Second, people won’t sign off on a technology unless they’re convinced it can work in practice. Differential privacy needs to prove itself in the field, in sufficiently many cases, in each vertical it can be applied to, before that happens.
- Finally, when privacy/security efforts are compliance-oriented, implementation can often be people doing the bare minimum. That might not be too great.
To be clear: this outreach work with key decision-makers is still valuable, and worth doing! But this isn’t what we’re focusing on in the immediate future.
Instead, we’re pushing for a bottom-up approach.
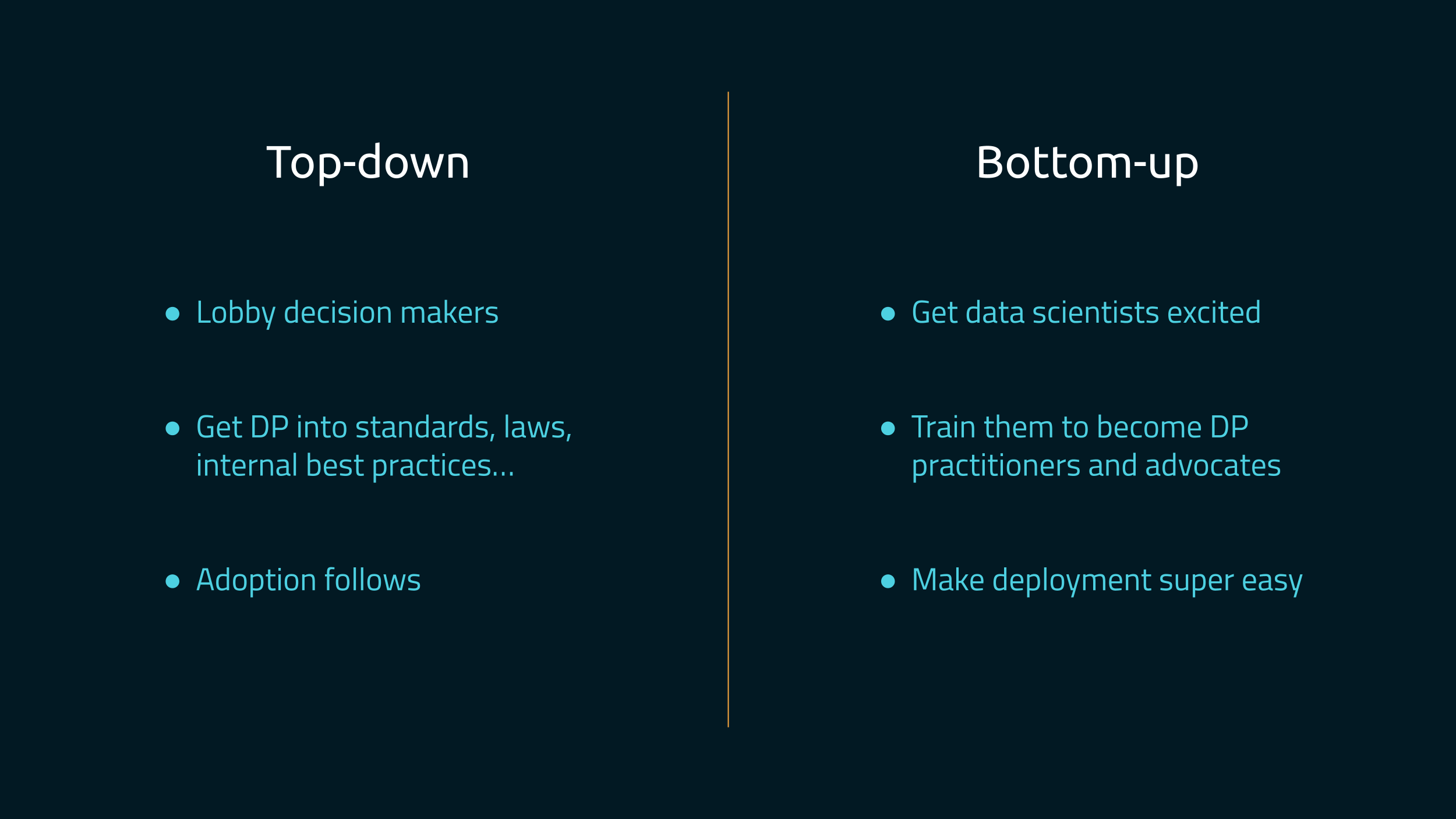
- First, we create excitement among data scientists and engineers, across the industry.
- Then, we create a well-lit path that makes it super easy for these people to go from “I’m curious what this technology can do” to “I know exactly how it will work for my use case!”
- And we create tools to make this entire process super easy, all the way to deployment.
Sign-off from decision-makers happens at the end of the process, not at the beginning. By that time, all they need to do is confirm that it works.
Note that as far as I know, this is what happened for most of the deployments that I could find described publicly. There wasn’t an executive giving the order to use differential privacy, out of the blue. Instead, individual teams of engineers and scientists built prototypes, showed that it worked in practice, did internal advocacy, and eventually got the go-ahead.
So, how do enable many more people and organizations to get to this point?
We have a vision, and we need your help.
We said that the way to get adoption is to make usable tools for differential privacy, and train people to use them. By the end, we want thousands of engineers and data analysts to become DP practitioners. What does that learning path look like in practice?
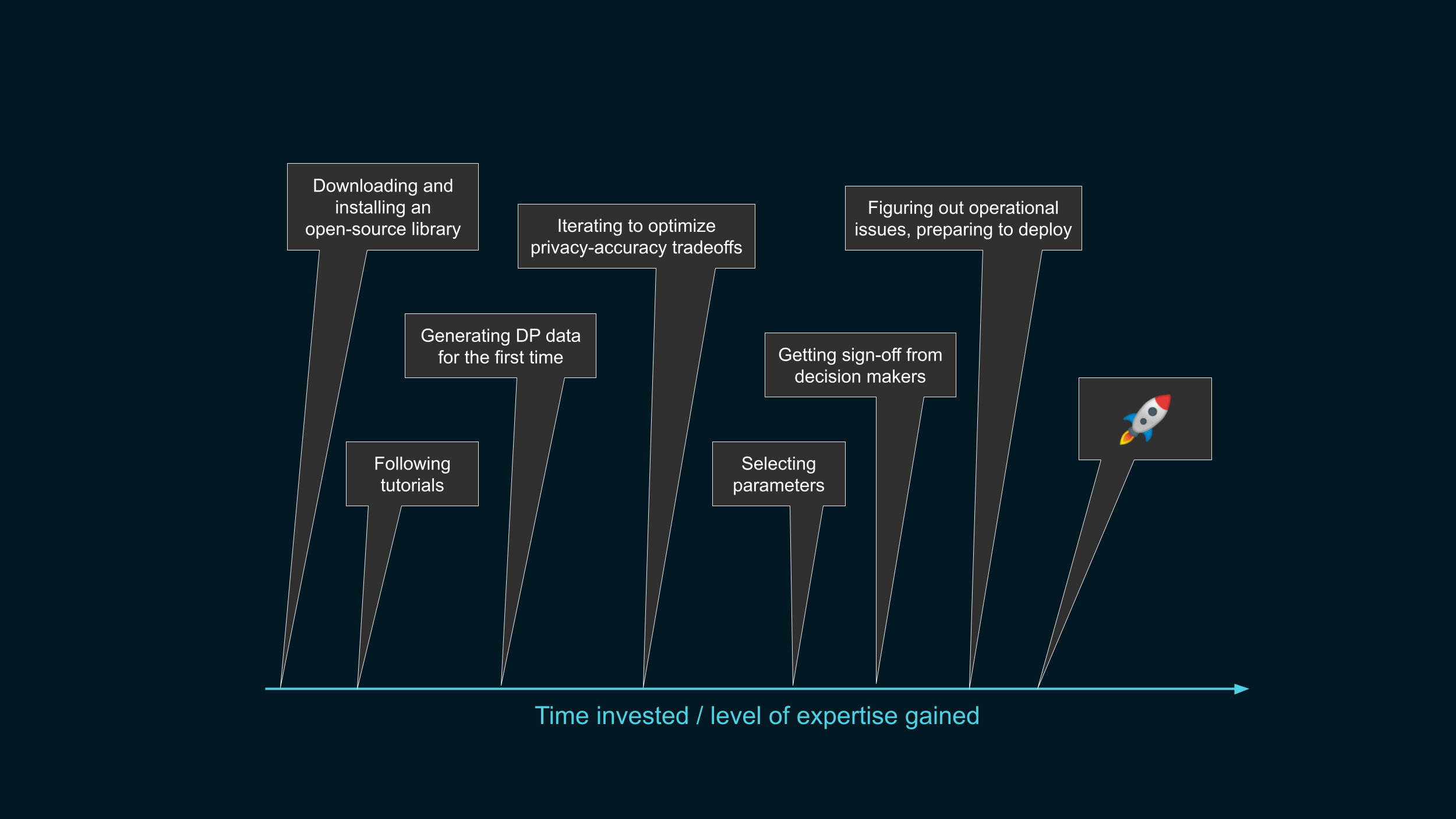
- First, people might hear about differential privacy, and decide to give it a try, using an open-source tool.
- They’ll follow tutorials to get the hang of it…
- … and maybe reach a point where they’re giving it a first try on their own data.
- Then, they’ll probably need to optimize privacy-accuracy trade-offs…
- … and if they’re convinced that this is workable, start thinking of which parameters would make sense for their use case.
- Once they get the sign-off from their hierarchy…
- … they will need to do a bunch of operational deployment stuff …
- … and end up shipping a differentially private data release.
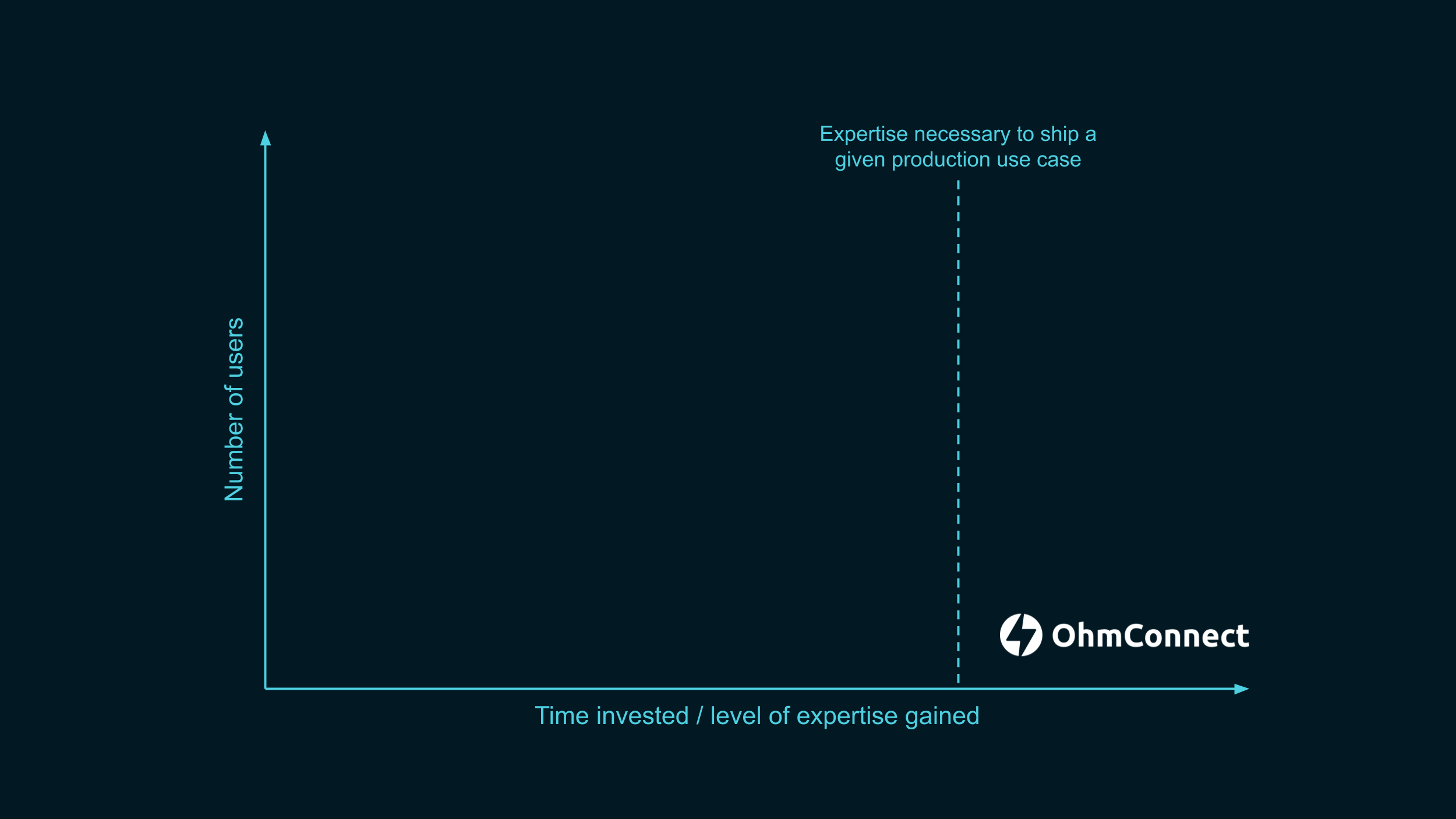
Our goal is to get people to that point on the right, where they can deploy DP to production.
As I mentioned earlier, I could find one small company that went further than this line. We want to get to many more such examples.
In fact, we’re going to visually represent how many people there are at each step of the process.
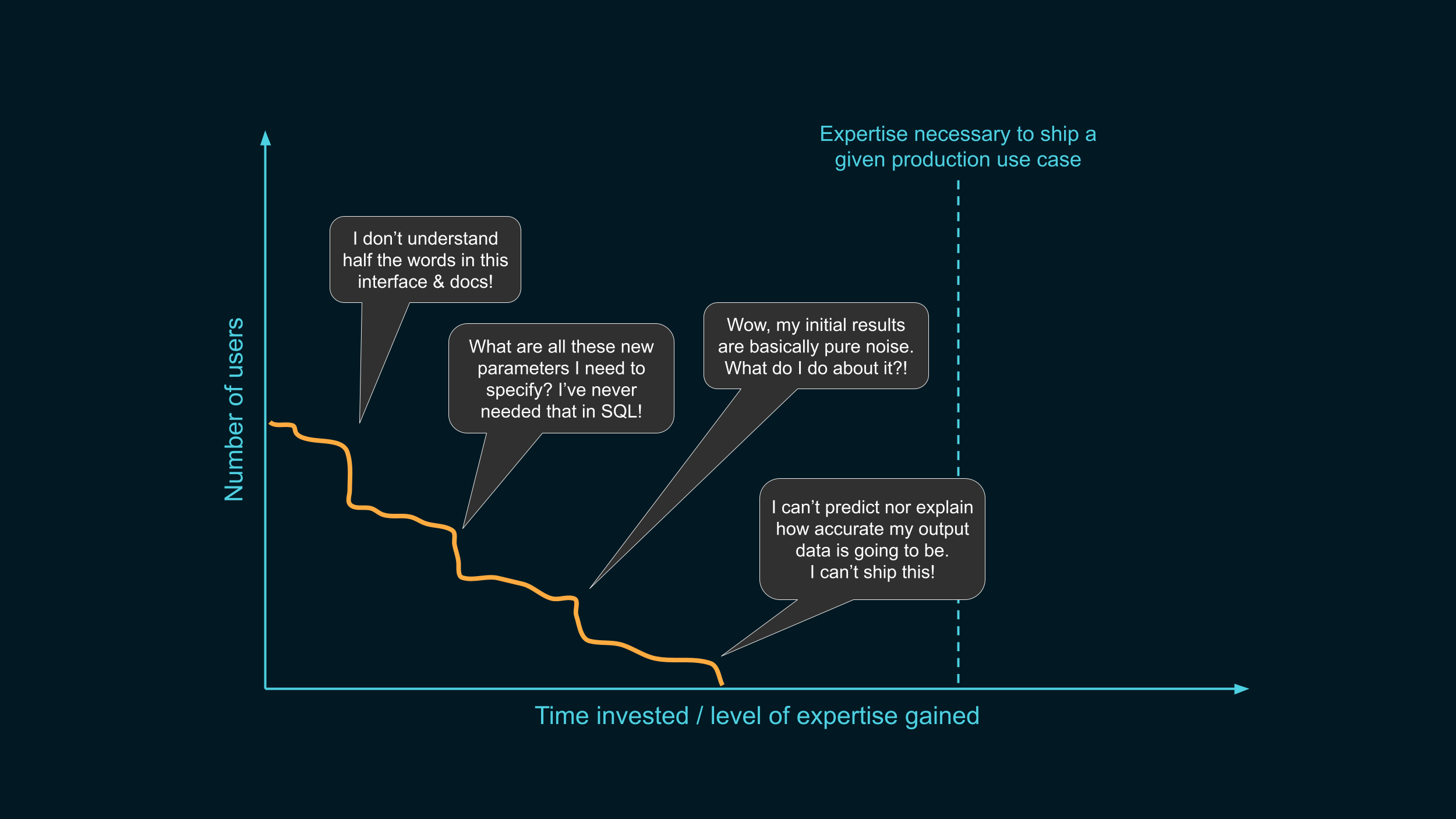
Today, the curve might look like this. Even though there might be some initial interest, almost nobody ends up crossing that line we’re interested in. So why is that?
We don’t know the answer for sure, but we’ve heard of a lot of hurdles that people encounter when trying to roll out differential privacy. Here are a few of them.
- First off, people might be immediately put off by how complex tooling looks like. If the interface & documentation looks like it was designed for people who already know what they’re doing, they might simply think “OK, I’m not the target audience”, and give up before even trying it out.
- Second, DP comes with additional requirements: things like group-by keys, or clamping bounds, are new concepts that people never had to think about before. People might think: why is it so hard to do even basic things that would take me 3 lines in SQL? And drop off, thinking that it’s just going to get worse from there.
- If people reach the point of trying it out on their own data, the initial results might be absolute garbage, because the strategy is extremely sub-optimal. This can be demoralizing, and make people feel like they won't ever make this work.
- Even if the results end up looking kind of reasonable when plotted on a graph, this might not be enough. People need stronger guarantees on how accurate the data is, and if the tool doesn’t provide this, this might also be a hard blocker.
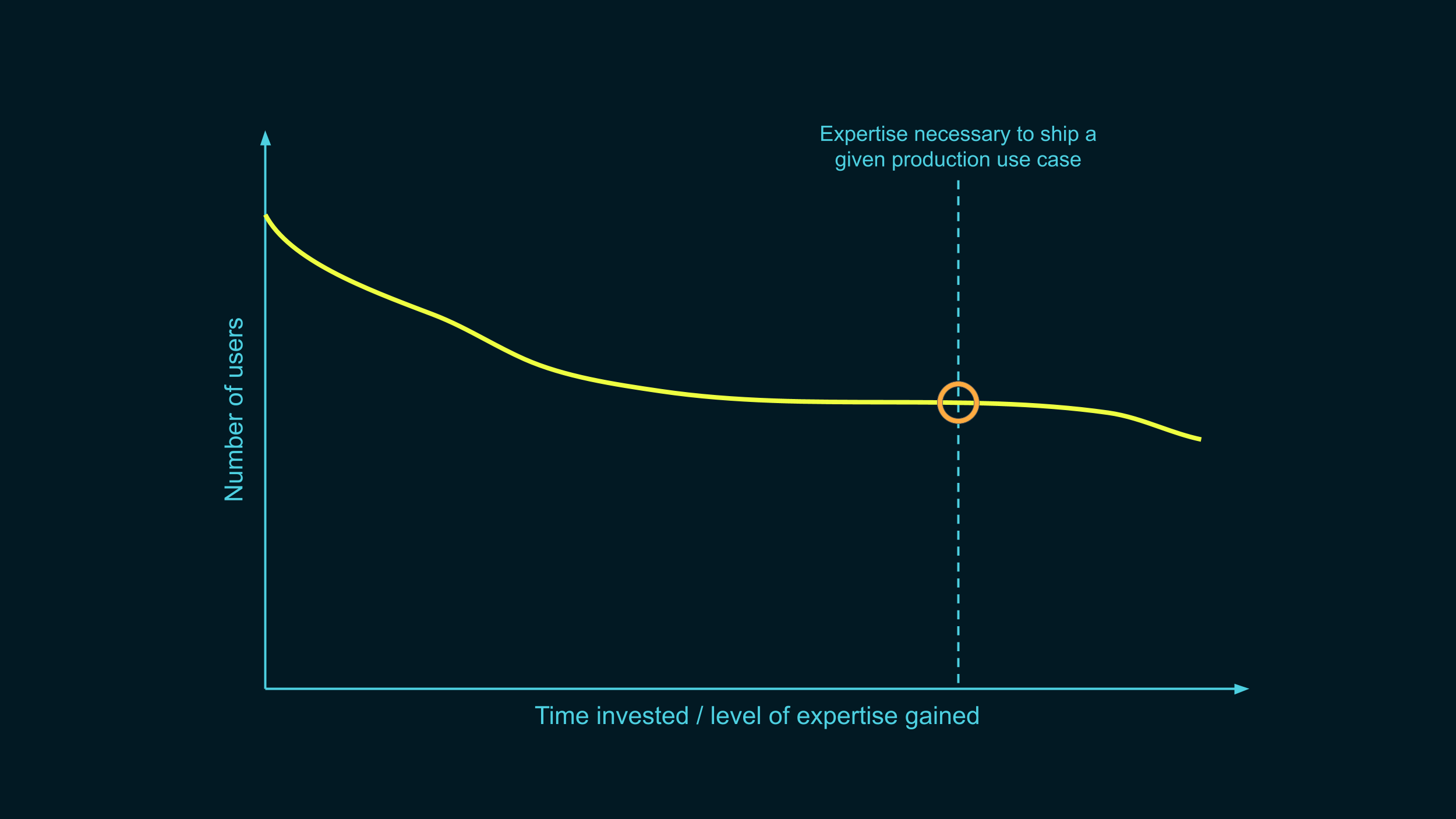
Instead, this is where we want to be. We won’t ever make the line entirely flat, that’s normal, every software project loses users in the learning process. But our goal is to maximize the number of people reaching deployment. We want the intersection point to be as high as possible.
OK, so how do we do it?
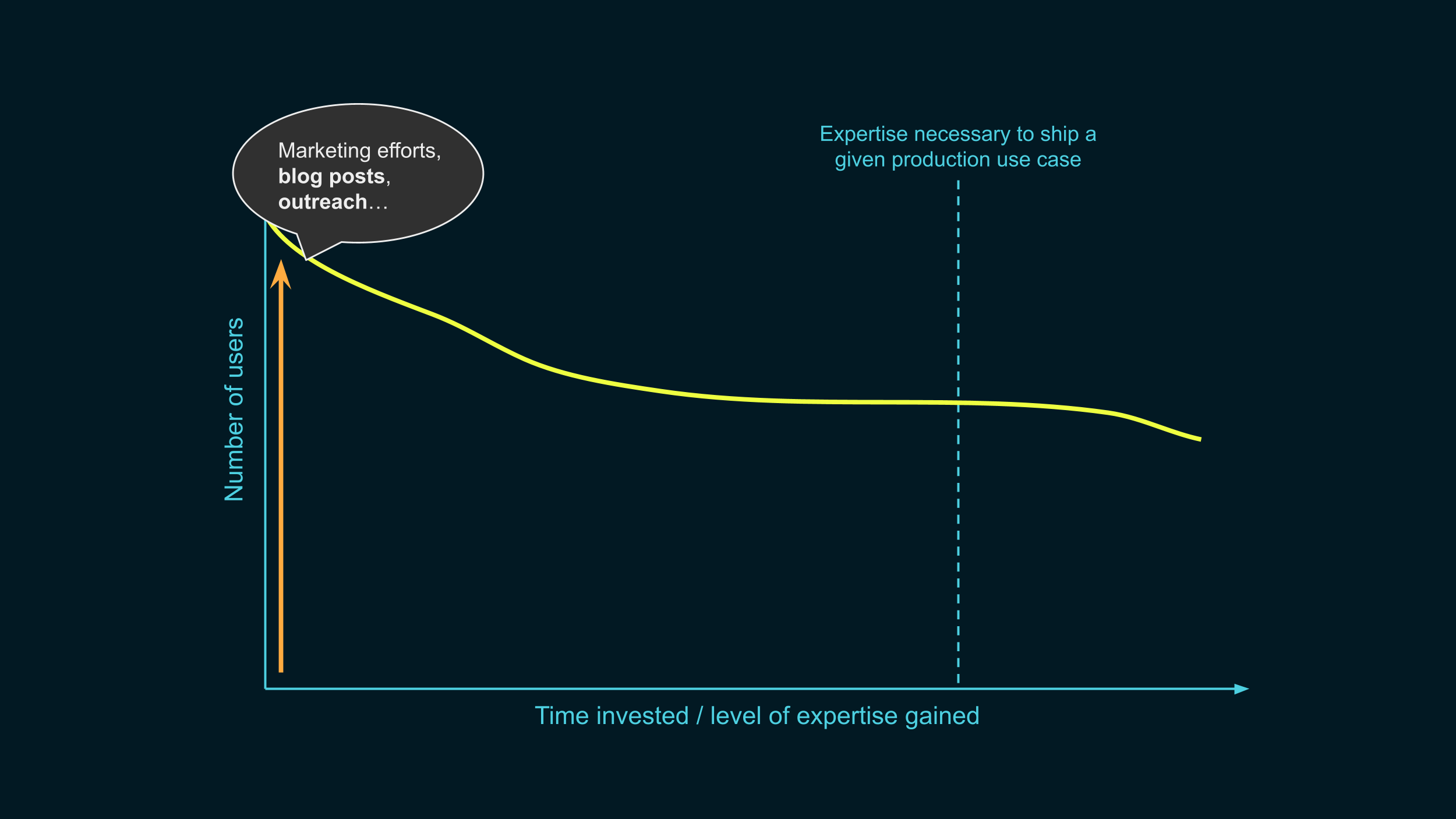
First, we make the line start higher. We want to get as many people as we can who know that differential privacy exists, and have an idea of what problem it solves. Further than that, we want to get them excited about trying it out.
Some of this is the job of companies like mine: we need to do a good job at marketing this technology.
But researchers can also help there: we need many more resources that are accessible to beginners, like blog posts! These serve the dual purpose of helping people learn, and of making our field more widely known to the public.
We also need y’all to contribute to the public discussions around data privacy, beyond research papers. There can be many examples of that kind of work.
- Opinion pieces in scientific publications, like the ACM magazines, or in newspapers, can do wonders to raise awareness.
- Participating to events or workshops discussing adjacent problems can be great to open your research horizons, and to socialize with people outside of your usual research community. Attending non-academic events around data privacy, in particular, can be eye-opening.
- Finally, getting into the contact list of a tech journalist whose work you follow is easier than you think! Reach out and let them know that you’re happy to comment on technical topics in your area of expertise, and they’ll be happy to take you up on the offer some time.
All of these can have a major impact. Thanks to everyone who is already doing this kind of work today! We need even more.
OK, once we made that line start as high as we could, what do we do next?
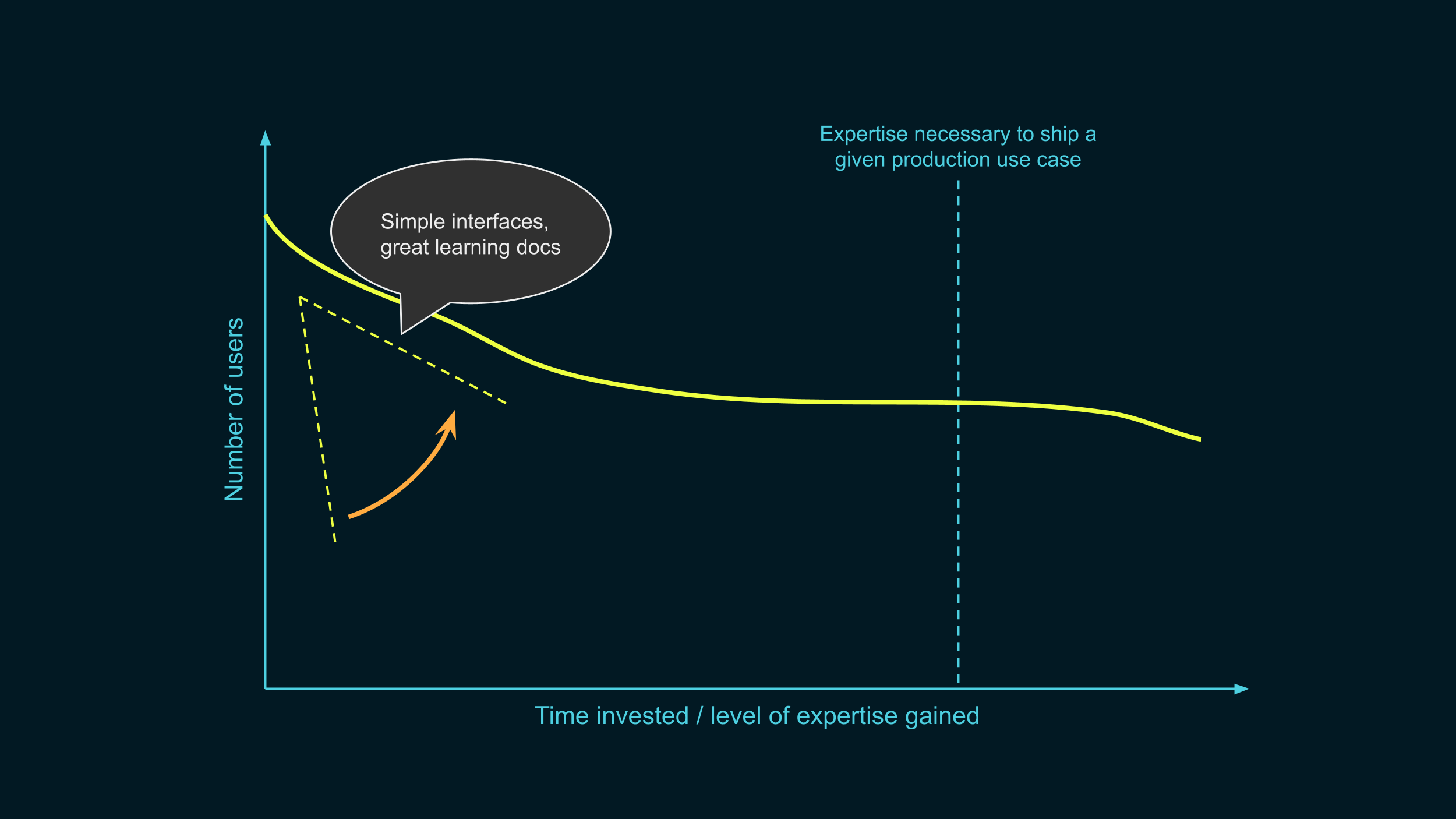
We make sure that we lose as few people as we can in the initial learning stages. We make that curve as flat as possible, avoiding those cliffs from earlier. We make the learning process as smooth as we can.
To do that, we need interfaces that are super simple to use, and a great onboarding experience. Let me give you a sneak peek of what the interface looks like on our platform right now.
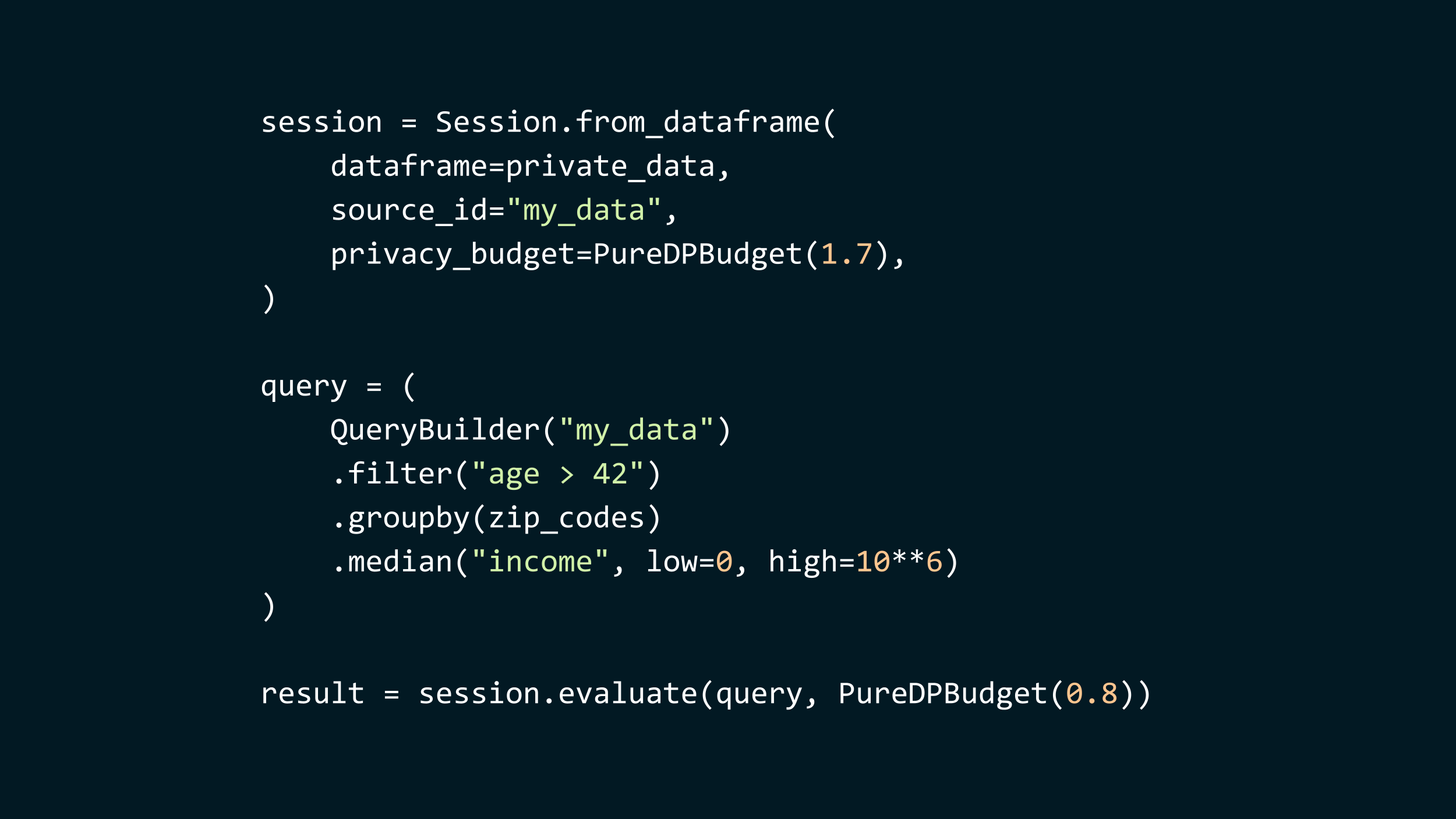
Our platform is built in Python, and runs on top of Spark, so we can scale to very large datasets.
- To use it, you start by defining a session. This session encapsulates your data, given as a Spark dataframe, and gives you clear privacy guarantees. Here, the library promises you that everything downstream of this session will satisfy differential privacy, with ε=1.7.
- Then, you write a query, using a Spark-like query language. Here, the query filters the records to only keep the individuals older than 42, then we group by zip codes, and we compute the median income for each zip code.
- Finally, you evaluate the query using a portion of your privacy budget, here, 0.8. The result is a regular Spark dataframe. We could, later, evaluate further queries, as long as we don’t spend more budget than was initially allocated.
There are a couple of things that will still seem unfamiliar to data scientists without prior experience with differential privacy: the way we specify group-by keys, for example, or clamping bounds. We’re working hard to make these even simpler and more accessible.
That’s what we’re doing. Now, what can the academic community do to help users in this initial learning stage?
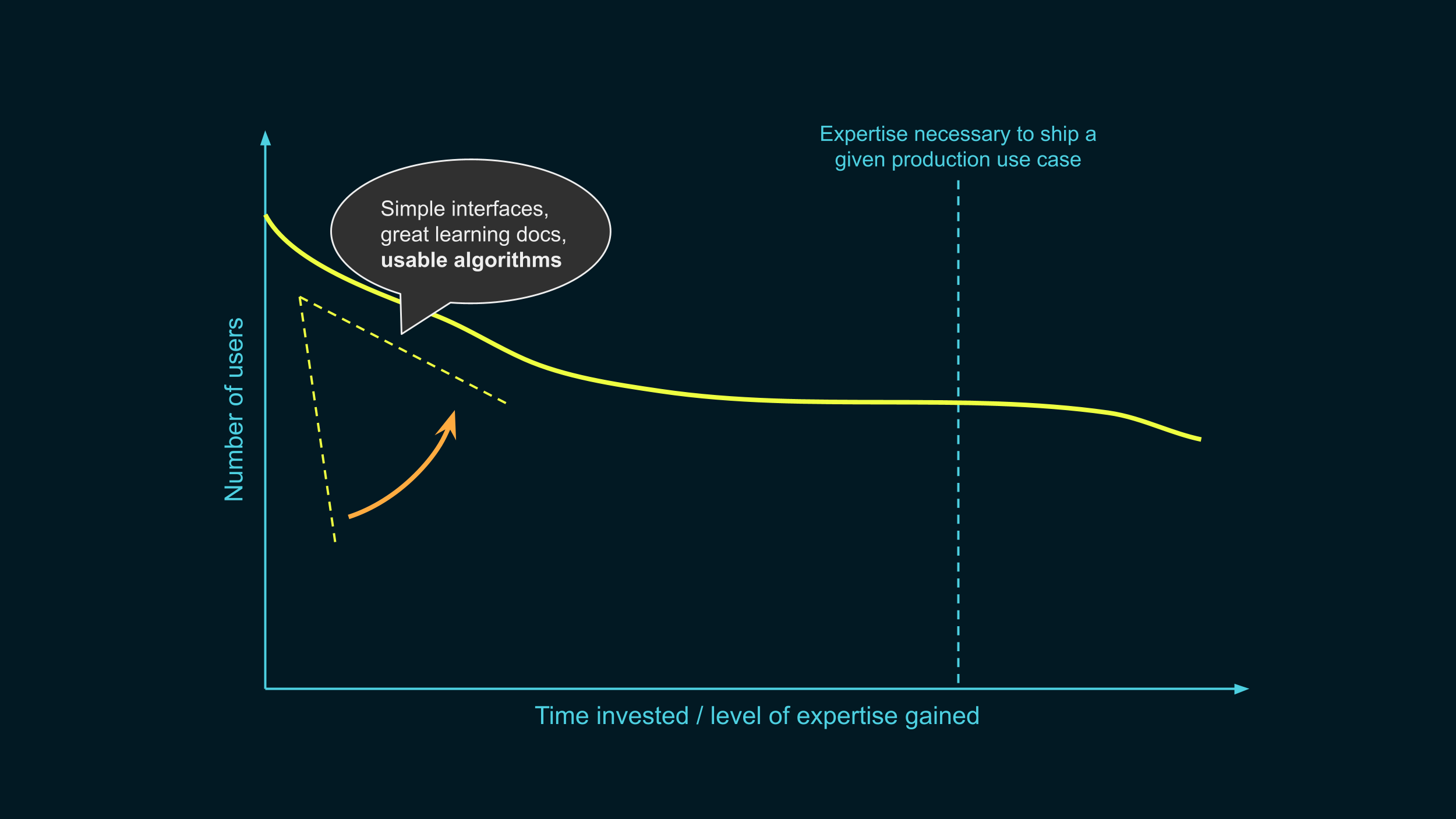
One way is by thinking about usability when designing new techniques to achieve DP. How many choices will a user have to think about before using a given mechanism?
Suppose, for example, that you found a novel a way to compute quantiles. It’s better than the state of the art, but it introduces new hyperparameters: for example, you need to discretize the data first, and the user can choose the granularity. Can you recommend a good default for this new parameter? If there is no universally reasonable choice, can you automatically and privately select it based on the data, using some portion of the budget?
Doing this will make it much more likely that people can use your fancy algorithms, even in the early stages of the process.
Ok, so that was the initial learning stage. What comes next?
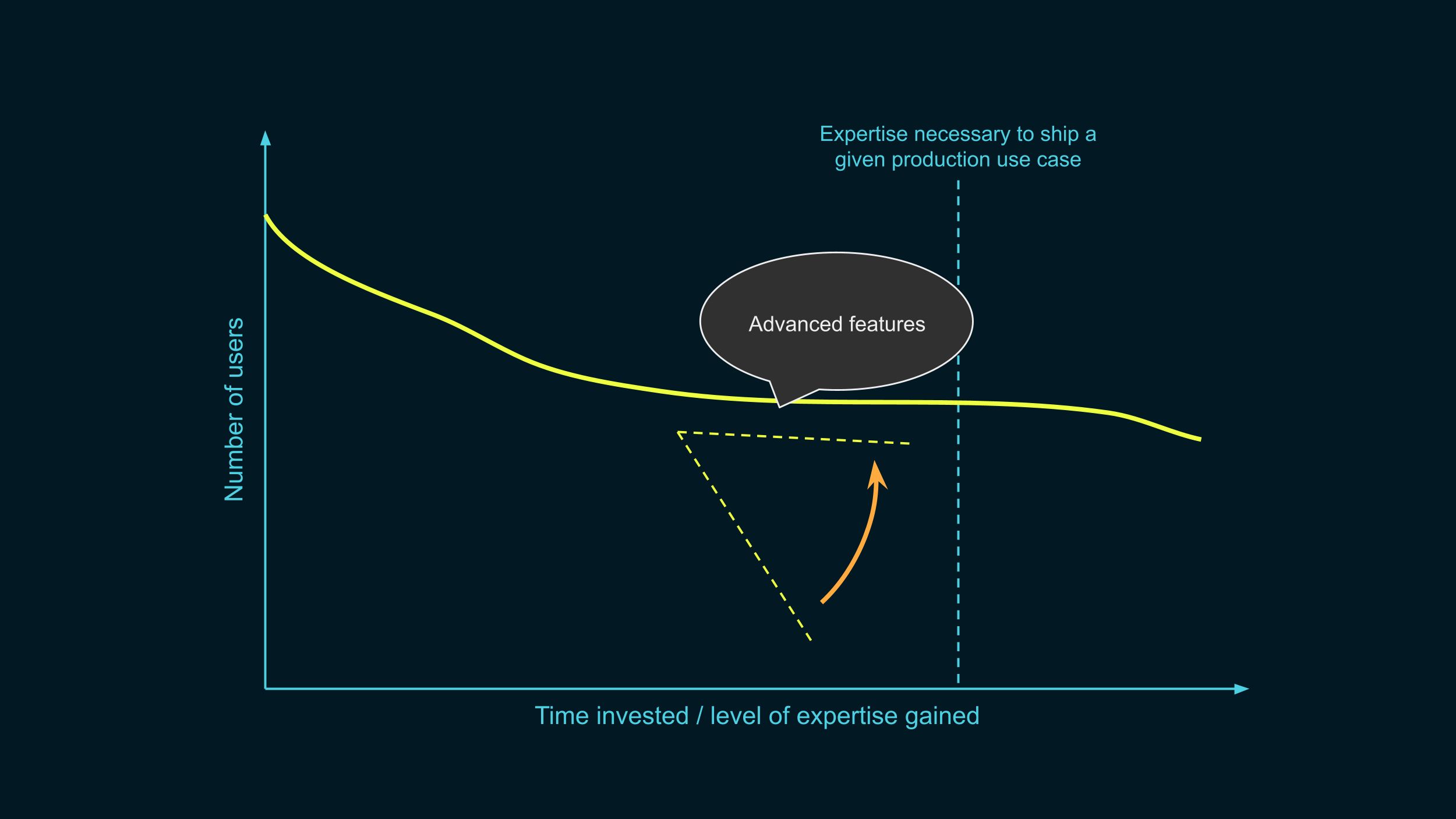
As people start moving out of the learning phase and closer to the deployment stage, we need to keep supporting them. Again, we want that curve to stay flat. We don’t want people to drop off just before the finish line.
Once people start trying to ship their initial idea to production, they start having more complex needs that require advanced features. For example, in one of the data releases we’re working on with the US Census Bureau, the goal is to publish statistics on various population groups, depending on geographic and racial characteristics. These groups can vary tremendously in size: in some cases, we can only publish total counts with reasonable accuracy, while in others, we also want to split these groups into more fined-grained categories.
This requires an adaptive algorithm. Let me show you what it looks like in our interface. It’s going to be little more complicated than the previous example, but don't worry, I’ll walk you through it step by step.

First, we set aside 10% of our total budget. Here, we use zero-concentrated DP, because each individual will contribute to many statistics, so we’re using Gaussian noise and tight privacy accounting methods. Note that here, switching to another privacy definition is as simple as changing the privacy budget type: the framework is extensible enough to make this kind of operation very easy.
We then use that budget to compute, for each population group, a total count of people. Here, we group by geography and race/ethnicity combinations.
Then, we augment these results by checking, for each of these groups, whether the count is below or above a certain threshold. Later on, we will want to do different things depending on the value of this column.

At this point, we have a table that tell us, for each group, whether the noisy count of people is above or below a threshold.
- We join our secret data with this augmented table. Each individual record is now associated with additional information telling us whether the group they’re a part of has a count below or above the threshold.
- And once we have this new, augmented private data set, we partition the session into two sessions, depending on the value of this column. One session will have part of the data, the other will have the rest. These sessions are allocated a given privacy budget; here, we use the entirety of the privacy budget we have left. That budget is depleted from the original session, and transferred to the new sessions.
![Two code snippets with accompanying visuals. //
total_session = new_sessions["total"]
total_counts = total_session.evaluate(
QueryBuilder("data_with_category")
.groupby(geo_races)
.count(),
privacy_budget=budget_90,
)
This is represented by the smaller histogram changing a little bit, using the
9/10 part of the budget. //
detail_session = new_session["detail"]
detail_counts = detail_counts.evaluate(
QueryBuilder("data_with_category")
.groupby(geo_races * age)
.count(),
privacy_budget=budget_90,
)
This is represented by the larger histogram, where each bucket is split in three
sub-buckets, using the 9/10 part of the
budget.](https://desfontain.es/blog/images/ppai-22-talk-17.png)
Now, we have two sessions, so we can do different things in each.
- For the records that are in small groups, we only compute the total counts, with the rest of the privacy budget. This is the same aggregation as earlier, but with more precise results.
- And for the records that are in bigger groups, we compute the counts at a more granular level, also including age. Here, the multiplication operator in the groupby correspond to doing the cross-product of groupby keys for different attributes.
Of course, the actual algorithm is a lot more complicated. We actually split the data in four different levels of granularity, so we have three different thresholds, ages are bucketed, we use more demographic information, and we compute a lot more things. But hopefully, this gives you an idea of what real-world use cases can require, and what kind of advanced features our platform can support.
OK, so that’s an example of what we’re doing to support people at this stage. Can the academic community also help flattening this curve, and make it easy for people to reach deployment?
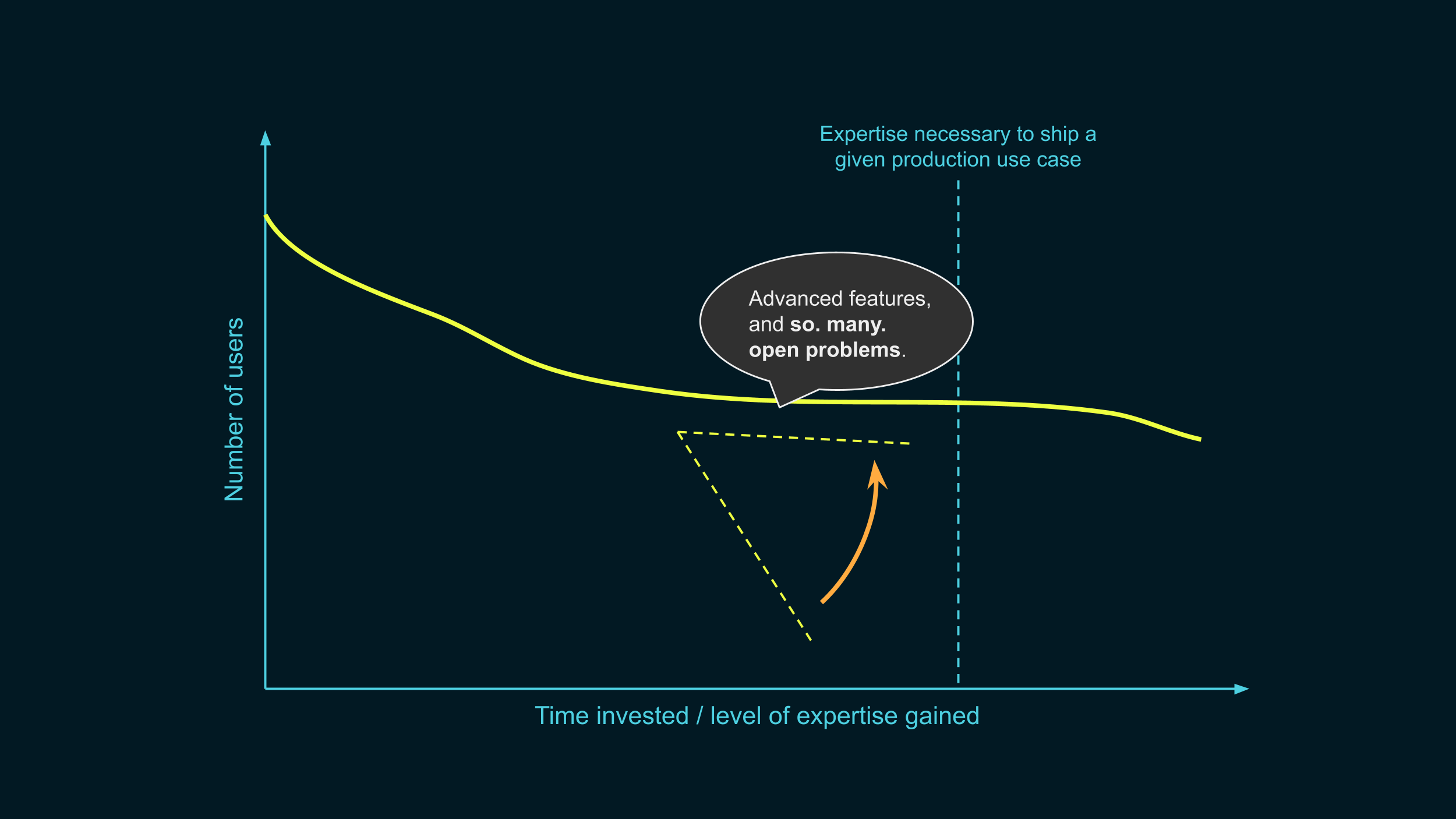
Yes. Yes, yes, yes. In this path towards deployment, there are so many open problems. People routinely need things that don’t exist yet. Our customers are constantly asking us for very reasonable things, natural requests that… turn out to be open science problems. This is why we’re hiring scientists, by the way.
Let me give you a distilled list of areas where we desperately need more progress in research and engineering.

First, explainability and transparency. Releasing private error measures along with the DP output is easy for simple mechanisms, but still hard for things like quantiles, or when clamping bounds are involved. More generally, can we explain to non-expert users what was done to the data? Can we give them a summary they can understand and use in later analyses? Finally, DP algorithms can introduce biases in the data – can we make these transparent, and allow data users to take them into account? Explainability and transparency are absolutely critical to build trust, and trust is key to adoption. We, as a field, need to have better answers for these questions.
A second one is decision support tools. Dashboards and visualizations that allow people to understand the privacy/accuracy trade-offs in their data, and fine-tune parameters, are critical. In our experience, this is often what makes people “get it”, and make them feel like they can actually use this tech. This is a promising area of research for visualization and usable privacy folks, but there are also complicated algorithmic questions here: how do we do that efficiently?
When people want to generate DP data, they don’t want to specify a budget: instead, it would be much nicer if they could decide what level of data quality is fit-for-use – good enough for their use case – and specify that as input to the algorithm. Note that these data quality measures are often interpreted as the error of a single noisy estimate or parameter. But in real use cases, it can be a lot more complex: for example, will the relative ranking of items based on noisy estimates be approximately correct?
Finally, operational aspects of DP are critical. How do we keep a good accounting of the privacy loss over time, for data releases that happen every day or week? How can we validate that the DP data is correct before publishing it? How should we handle failures? How do we detect drifts in accuracy, and how should we handle these alerts? Work on these topics is starting to emerge in academia, but there is a lot more to be done.
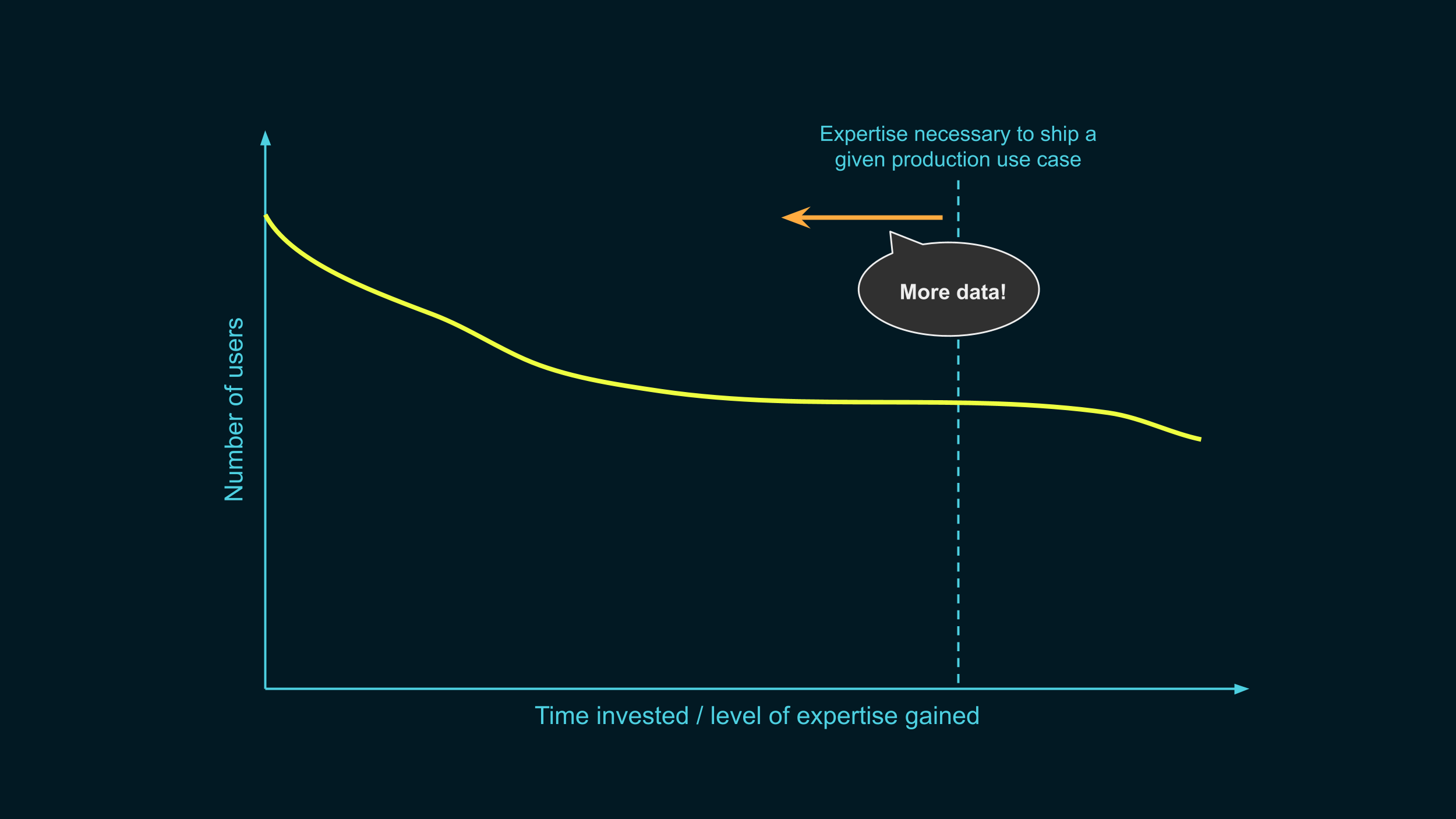
Back to our curve. One last thing we can do is lowering the level of expertise necessary to ship DP to production is as small as possible. The faster people get there, the less likely they’re going to drop off.
This first requires more data: what do people actually need to do? Once we know, we can build the advanced features that people need, and build interfaces that make them easier to use.
The call to action here is: if you know of more people using differential privacy in practice, try convincing them to communicate about this! Even when there isn’t novel science involved, it’s still worth telling the world what you did, and ideally, why you did it. This way, we can know what problems people encounter in practice, and what are the most pressing issues to solve to increase adoption. As a an added bonus, communicating about your use case for differential privacy is a great way to foster trust among stakeholders, and to convince other people to also try using DP!

There are two more ways you can help.
- If the little code snippets I showed sounded interesting, and you’d like to play with our platform and give us feedback, let us know! We’re happy to give you a preview before our open-source launch later this year.
- Finally, if you’d like to apply your research skills to hard, impactful real-world problems, and work with a great team, drop us a line! We’re looking for scientists in Europe and in the US.

Thanks again for the invitation and for attending this presentation! I'm looking forward to your questions, and I'm also happy to continue the conversation by email or via Twitter.