

Empirical privacy metrics: the bad, the ugly… and the good, maybe?
This post is a transcript of an talk I presented at PEPR in June 2024. The talk was recorded and published online.
Hi everyone! I have great news!
We just solved privacy!

In fact, I don’t know why we even need this conference anymore!
All we need to do is take our data, put it through a synthetic data generator, and — tadaaa! We get something that we can use for all of these pesky data sharing or publication or retention use cases. You know, all the ones where the lawyer told us that we needed to anonymize our data, and we had no idea where to start.
Anonymization is hard, but synthetic data is easy!
…
Now, if you’re like me, you don’t take claims like these at face value.
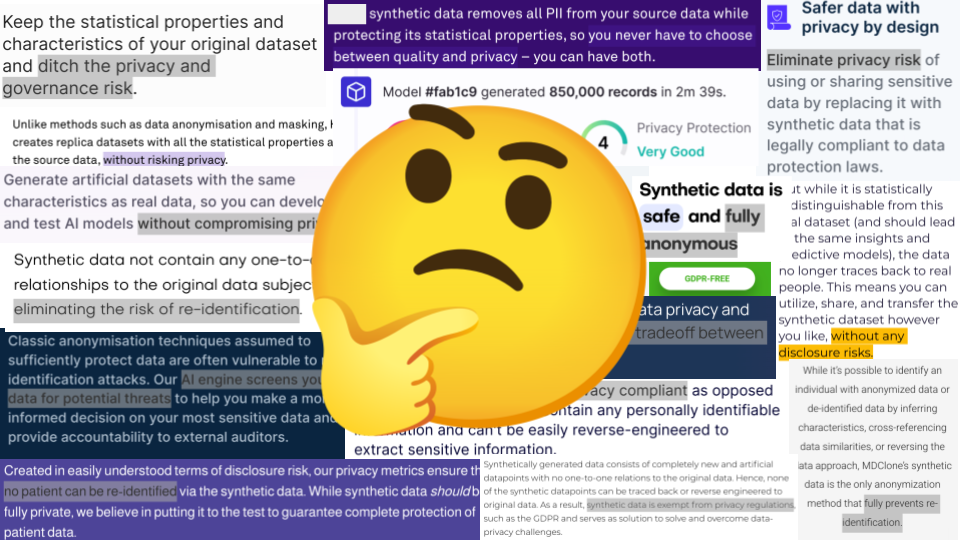
And a natural question you might have is: why does this stuff actually preserve privacy? All these marketing claims… how are they justified?
In some cases, the answer is… eh, you know. It’s synthetic. It’s not real data. That means it’s safe. Stop asking questions.
Now, you’re all privacy pros, so I trust that if someone gives you that kind of hand-wavy non-answer, you would smell the bullshit from a distance.
Sometimes, though, the answer seems to make a lot more sense.

That answer is: we know it’s safe, because we can measure how safe it is.
We can generate some data, do some calculations, and tell you whether this data is “too risky”, or whether you’re good to go.
That sounds great!

Hi. I’m Damien, and today, I’m really excited to tell you all about empirical privacy metrics.
The first question you probably have is: how do they work? What do they measure?
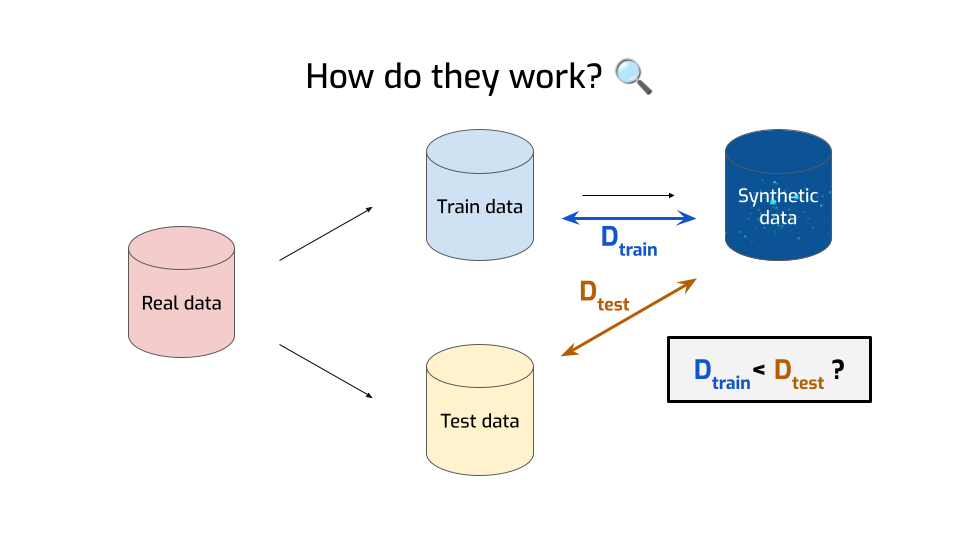
In this talk, I’m going to focus on one kind of metric, which is both the most reasonable-sounding and the most widely used. They’re called similarity-based metrics. The idea is relatively simple.
- First, you take your data and you split it in two parts — the train data and the test data, just like what you do in machine learning.
- Then, you use only the train data to generate your synthetic data.
- Then — and this is where it gets interesting — you compute the distance between the synthetic data and the train data. There are many ways to compute the distance between two distributions; you end up with different metrics depending on the distance you choose. Here, we’ll ignore the details, and just say it’s a measure of how similar the two are to each other.
- Then, you compute a second distance, this time between the synthetic data and the test data.
And once you’ve got two numbers, you’re doing the natural thing and compare them with each other. Is the distance to the train data smaller than the distance with the test data?
If yes, that’s… is that bad or good?
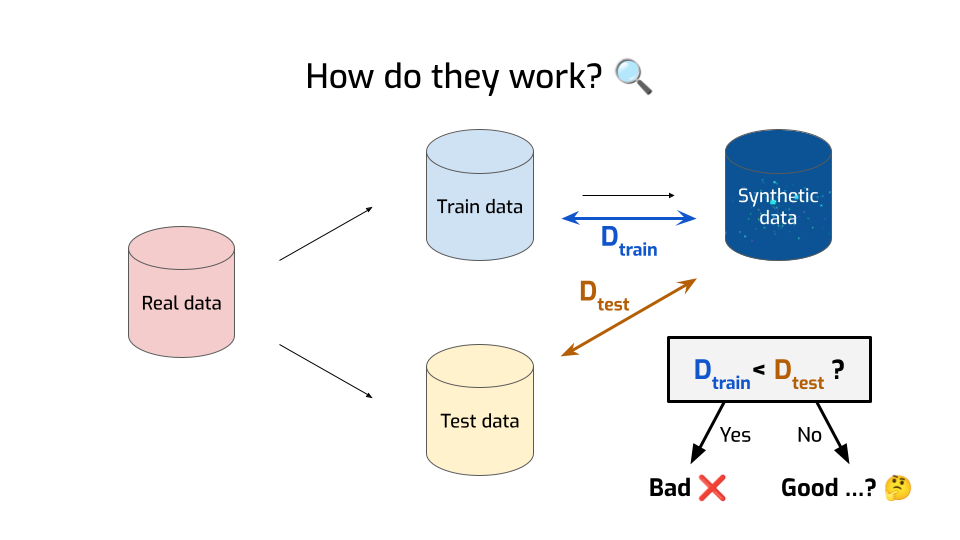
Correct! That’s bad. That means we generated records that are close, not just to the real data, but to the specific points that we used for generation. We didn’t just end up matching the distribution well, we overfit to individual data points. That could be a sign that we leaked some private information. So, that’s bad.
Conversely, if the two numbers are roughly the same, or even if the distance to the train data is larger, that means we’re fine. We didn’t leak any sensitive data.
Right?
… Right?
I mean, that does sound reasonable. But I’ve said something about "bad and ugly" before, so you can probably see where this is going.
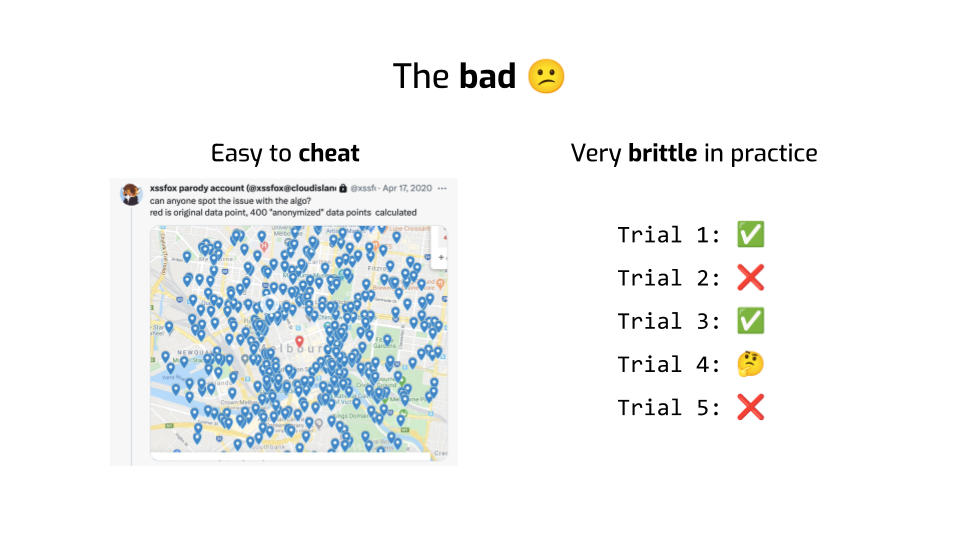
So let’s get into it. Where’s the bad?

First, it’s really easy to cheat at these metrics. All we need to do is to make sure that the synthetic data isn’t “too close” to the training data. Except if we do that of course, we do leak information — exactly what’s happening in this screenshot of some COVID 19 tracking app. Knowing where real data points are not gives us data about where they actually are.
You could tell me — that’s not a real problem. We’re not making algorithms that do this sort of nonsense. We’re not cheating in real life.
Except… you’re using machine learning algorithms!
You’re giving your data to a neural network, you don’t really understand how it works, but you tell it: go optimize for these metrics. I want good utility and good privacy, and this is how both of these things are defined. Go achieve both objectives.
Guess what? Neural networks are going to cheat! That’s what they do! They’re just not going to be as obvious about it!
Second, the process I described earlier has some inherently random aspects to it. For example, which data are you using for training vs. for testing? Or what’s the random seed you used as part of your machine learning training?
So what happens if you change those? Does your empirical privacy metric return the same result?
Researchers tried that, and found shocking levels of randomness. Sometimes the metric tells you everything looks good, and then you re-run the same algorithm on the same data and it tells you it’s very bad. So that doesn’t exactly inspire confidence.
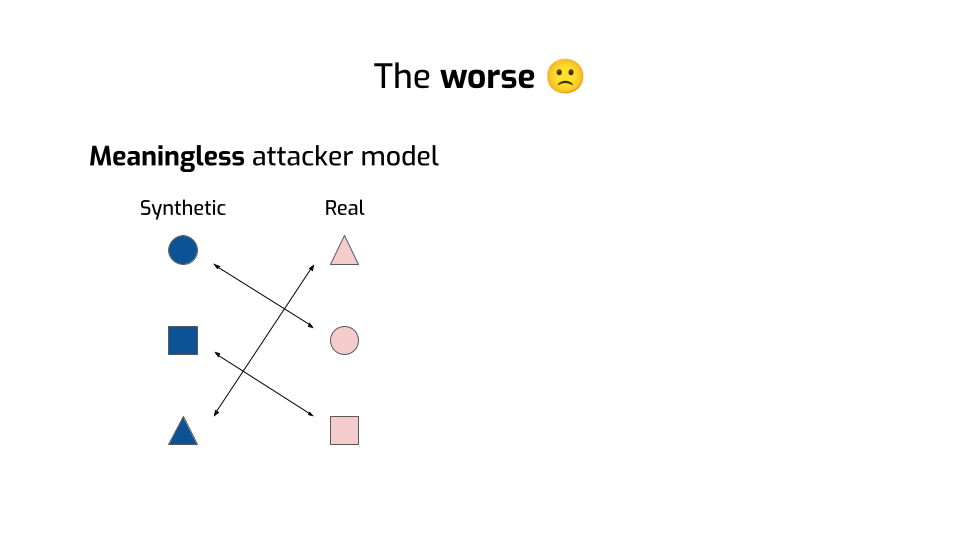
OK. There’s worse. I count at least two much more profound issues.
One is that these similarity-based metrics assume an attacker who’s trying to do something really weird. They have synthetic data points, then they also have real data points somehow, and their goal is to link the two together. If they can accurately draw some of these lines, then they win.
But that’s not what attackers do in real life! There can be leakage even if no such line exists! Attackers can do things like reconstruction attacks, exploit the details of your algorithm, use auxiliary information… Sometimes they can even influence your data!
The distances we saw earlier — they don't model any of that. Their threat model is essentially meaningless.
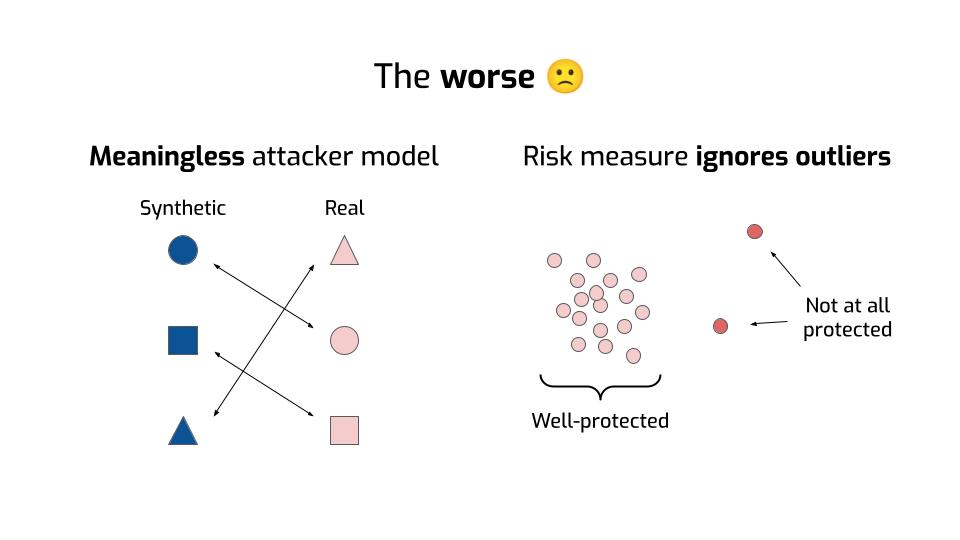
Finally, remember how we were computing the distance between two distributions earlier? This single number is an averaged metric across all data points. So at best, it tells us how well we protect the average person in the dataset.
But — and I cannot stress this enough — everyone needs privacy guarantees! Including outliers! Especially outliers! If your approach works fine for most people, but leaks a ton of data for demographic minorities, that’s bad! I’d argue that it’s even worse than a system that leaks everyone’s information: at least you would notice and fix it!
So these four problems I talked about are serious. Suppose we somehow fix all of those. Does that mean we’re good?
I don’t think so. The design of these empirical metrics is bad, but the way they’re used is much more problematic.
Fundamentally, what are these metrics trying to do?
They’re trying to quantify risk. They tell you: there’s some kind of risk scale. Some end of the scale is great, the other end is bad.
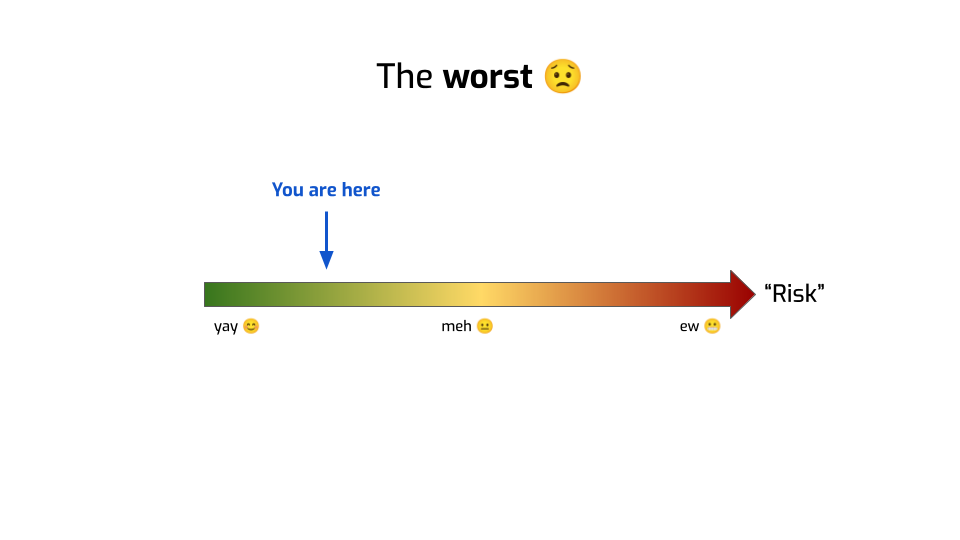
Well, we’ve seen that maybe we’re not exactly measuring risk, more like “risk”.
But more importantly, people building and selling synthetic data are basically telling you: you can generate some data and measure where you are on the scale. Like, for example, there. You’re in the safe zone. You’re fine.
But that’s not what empirical privacy metrics can ever tell you, even if you fix all the problems I talked about!
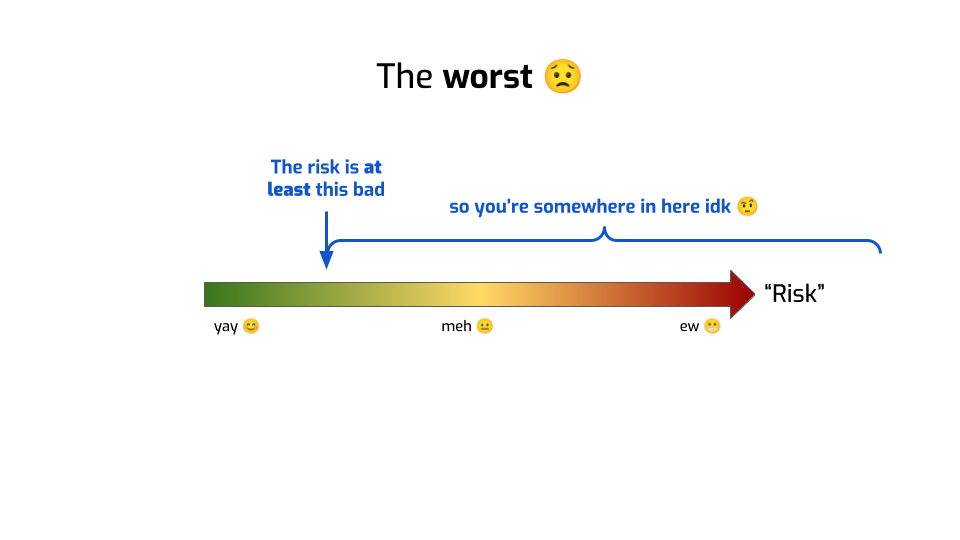
At most, they can tell you something like: you’re somewhere here.
We know for sure that you’re not on the left of this. Maybe we ran an attack and found that this is the success rate of the attack. So it’s at least that bad.
But we don’t know how much worse this can get! Maybe a smarter attack would have a much better success rate! We have no way of knowing that!
I want you all to keep this framing in mind when people are selling you privacy tech and presenting empirical metrics as the solution to your concerns. They will — I can guarantee it, I read all their marketing — present it as a thing that can allow you to verify that your data is safe.
This is a lie, and the sad thing is — I don't even think that the people repeating it realize that this framing is dishonest. You got a number, you know? On a scale labeled "Risk"? You just really want to believe in it!
OK. I promised you bad and ugly. I gave you bad, worse and worst. Where’s the ugly?

Let me ask you a question.
Why is the state of empirical privacy evaluation so bad? Why do people use such garbage metrics, and make such dishonest claims?
I don’t believe in bad people. Whenever something’s broken, my first question is always: what are the incentives at play?
Here, what are the reasons why synthetic data vendors would want to improve their metrics? What would structurally motivate them to do better?
Let’s make a pros and cons list, starting with “why would they not do that”.

- Obviously, this is more work. We have metrics today, if we need to change them, that’s feature work that we could use to do something else instead. So that’s hard.
- If we make metrics better, they might find more privacy issues. That’s not great, because we sold a whole lot of that stuff as being safe.
- Also, making metrics stricter is going to make it harder to design synthetic data generation tools going forward. That sounds inconvenient.
- This idea that you can generate data that’s privacy-safe, where you don’t have to worry about compliance anymore… that’s a major selling point. If we start poking holes in this story, our stuff will become harder to sell.
- Finally… by and at large, people don’t really understand this anonymization thing. Synthetic data seems to make sense, and the idea of measuring privacy definitely sounds reasonable.
Here’s something I learned the hard way: when your anonymization technique leads to bad utility, people notice. They bang at your door. They say — this is crap. I can’t use this. But when your technique is unsafe, who’s going to notice? Nobody, before someone with bad intentions does.
OK, so those are reasons why vendors would not spontaneously be incentivized to make things better. What are the pros, though? What are the reasons for change?
No, seriously. I’m asking. What are those? Do you know?

Because I don’t.
There just aren’t a lot of structural incentives pushing folks to do better. Adopting a truly adversarial mindset is hard. This stuff is complicated. The metrics seem to make sense. Why change any of it?
One possible reason is because you, as buyers of this technology, as privacy professionals, as standard bodies and regulators even, are asking for it. My one call to action for you is: please start doing so! Please demand better answers from synthetic data vendors! The people in your data deserve it.
Now, is there a path to redeem these empirical metrics? Can we ever get good answers to the questions we should ask to synthetic data vendors?
I think so!
First: quantifying risk is a great idea. Having a goal with a number attached to it is a fantastic motivator. We can track progress. We can quantify trade-offs.
Estimating empirical risk is also super valuable! We should absolutely run attacks on our privacy-critical systems and measure their success. I, for one, want to know where my system lands on this nice risk scale. So how can we do that in a better way?
For starters, we need better metrics. We need to measure something meaningful. Otherwise, I refer you to Lea’s excellent talk from last year: bad metrics lead to very bad decisions.
The attacker model needs to make sense. It shouldn’t be too easy to cheat. It should capture the risk for the least protected people in the dataset. It shouldn’t be too random.
There are some recent papers that propose new, better ideas on how to quantify privacy risk. We’re far from having a definitive answer there, there’s still a lot of work to do.
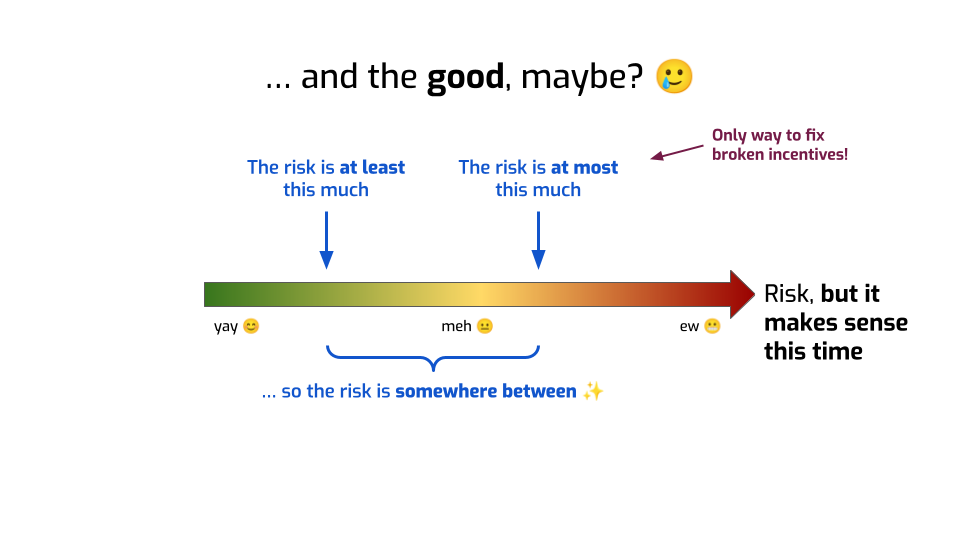
Second, we need to frame these metrics better. We need to accept that they’re only giving us part of the story.
These metrics could be great at telling us “hey, there’s a problem there, we can show that the risk is high”. Like an alert, a warning sign. The absence of alerts doesn’t mean everything is fine, but warning signs are still super useful.
Third, we need to use empirical privacy metrics in conjunction with other ways of quantifying risk, that give provable, worst-case guarantees.
Of course, in a complete shock to everybody who knows me, I’m talking about differential privacy. But I’m not saying that it’s the only answer! Sometimes — often, actually, especially with synthetic data — you need large privacy budgets to get good utility with differential privacy, so relying on the mathematical guarantee alone can feel a little iffy. Complementing that with empirical analyses makes a lot of sense, and can provide a much more complete picture of the risk.
This last part is also important because it’s the only way I know of to align incentives a little better. Again, vendors have no incentive to improve metrics and being more honest in marketing. I hope you’ll call them out on it, that might change the balance a little bit, but still. By contrast, when you quantify worst-case risk, then incentives are much more aligned: doing more work leads better privacy-utility trade-offs. It structurally tends to keep you honest. You have to quantify everything. That’s another reason why we like differential privacy :-)

If you want to hear more about this last thing, come talk to my colleagues and I at Tumult Labs! We help organizations safely share or publish data using differential privacy.
On the right, you can find the links to my LinkedIn and Mastodon profiles, and to my blog post series about differential privacy.
Thanks for listening!
I’m grateful to Gerome Miklau, Ashwin Machanavajjhala, and Hari Kumar for their excellent feedback on this presentation.