

Anonymiser des données pour de vrai avec la confidentialité différentielle
En avril 2024, j'ai été invité par les équipes techniques de la CNIL pour donner une présentation sur la confidentialité différentielle lors d'un séminaire de recherche du LINC. La vidéo de cette présentation a été ensuite publiée en ligne. J'ai reproduit mes diapositives et la transcription de cette présentation ci-dessous, après quelques modifications.

Bonjour à toutes et à tous !
Je m’appelle Damien et j’ai une mauvaise nouvelle.

La mauvaise nouvelle, c’est qu’on peut pas prendre des données appartenant à des individus et publier ou partager des statistiques sur ces données, sans aussi révéler de l’information sur des individus spécifiques.
Ça, c’est une vérité fondamentale, qu’on peut formaliser et prouver avec des maths. Comme on m’a fait promettre de ne pas vous parler de maths, à la place, je vais vous donner deux exemples qui illustrent ce phénomène.
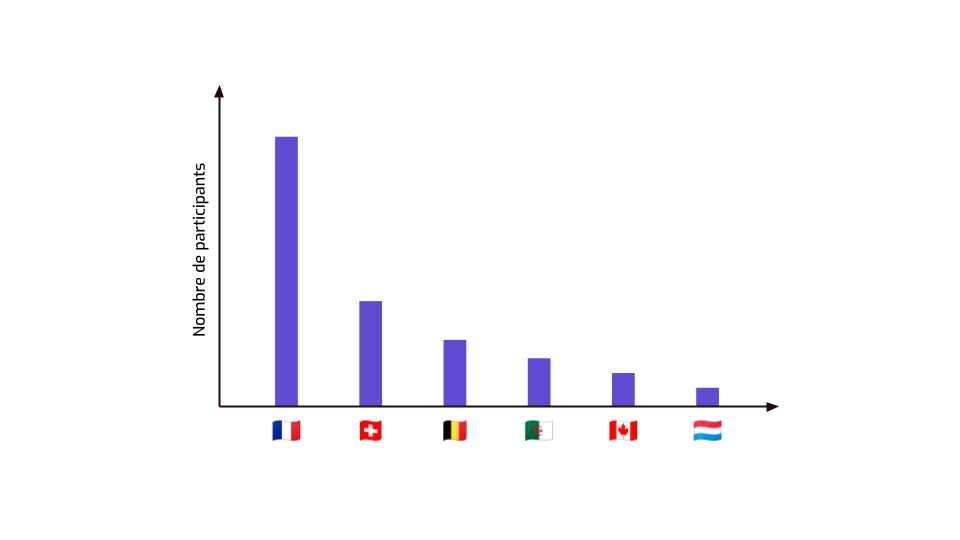
Supposons qu’on organise une conférence francophone de protection de données. On demande aux participants et participantes de remplir un formulaire où leur pose des questions comme « quel est votre pays d’origine ? ».
La conférence dure plusieurs jours. À l’issue du premier jour, on observe la distribution suivante. Il y a plusieurs personnes provenant de chaque pays, donc on se dit : « ce sont des données statistiques, pas individuelles, on peut sans problème les publier sur le site de la conférence ».
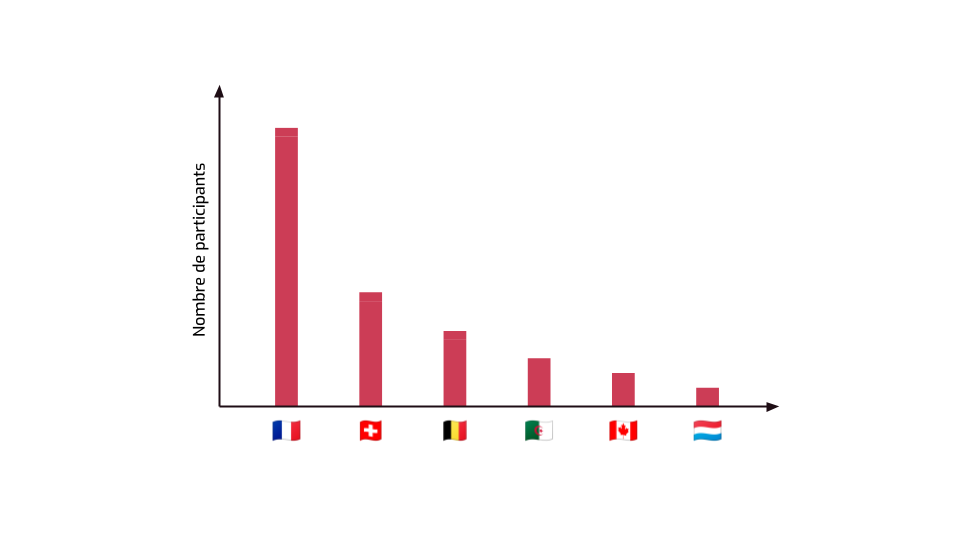
Le lendemain, il y a quelques nouveaux participants, donc les données sont mises à jour sur le site.
Moi, j’étais à la conférence, et je me souviens des données publiées la veille. Donc je peux calculer la différence des deux…
… et savoir qu’il y a exactement trois nouvelles personnes qui n’ont pas pu assister au premier jour.
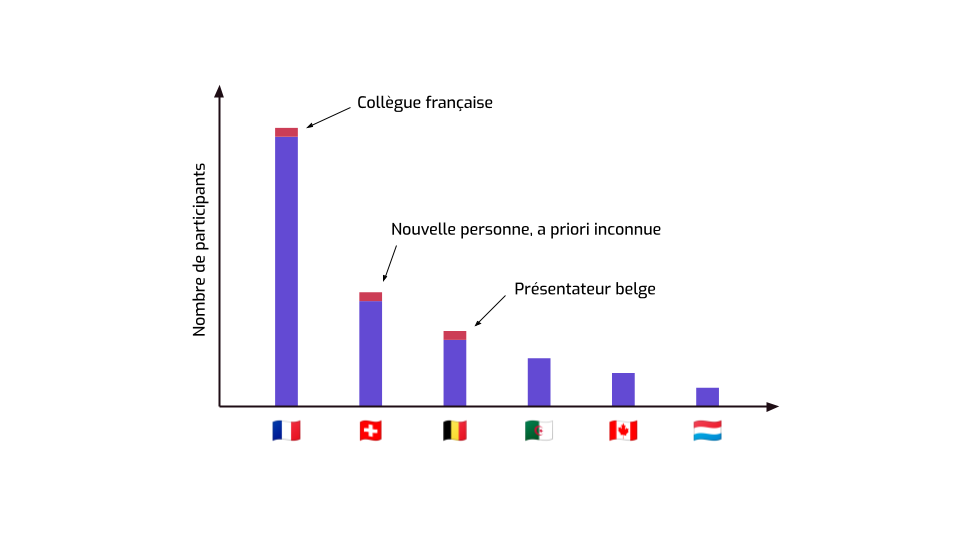
Mais attendez une minute.
- Une d’entre elles, je la connais — c’est une de mes collègues, arrivée aujourd'hui. Je sais qu’elle est française. Ce petit bout de données à gauche, ça correspond exactement à elle.
- L’autre, c’est quelqu’un qui donne une présentation et qui s’excuse de ne pas avoir été là hier. Sa bio indique qu’il est belge, donc il est là dans les données statistiques.
- Donc la troisième… Ça doit être cette autre personne dans l’audience, que je suis sûr de ne pas avoir vue hier. Je ne sais pas encore qui c’est, mais je viens d’apprendre qu’elle est Suisse.
Et ça… c’était pas vraiment supposé arriver. J’ai appris quelque chose à propos d’une personne unique, alors que tout ce qu’on a fait jusqu’à maintenant, c’est juste publier des statistiques.
C’est un premier exemple qui illustre la mauvaise nouvelle de tout à l’heure : on a fait fuiter de l’information individuelle sans le vouloir.
Vous allez me dire : « Damien, ton exemple est un peu tiré par les cheveux. Ce genre de truc, ça n’arrive pas dans la vraie vie. »
Laissez-moi vous parler du bureau du recensement américain. C’est l’équivalent de notre INSEE en France. C’est une agence publique qui collecte des données sur tout un tas de choses, y compris des individus, puis qui publie des statistiques démographiques et économiques sur le pays.
En 2010, ils ont, comme tous les 10 ans, publié un tas de statistiques démographiques. Combien de gens vivent à quel endroit, quels âge ils ont, quelles sont leur caractéristiques ethniques, combien y a-t-il de personnes par foyer, ce genre de chose. Plus tard, ils ont voulu estimer à quel point ces données pouvaient être réidentifiables.
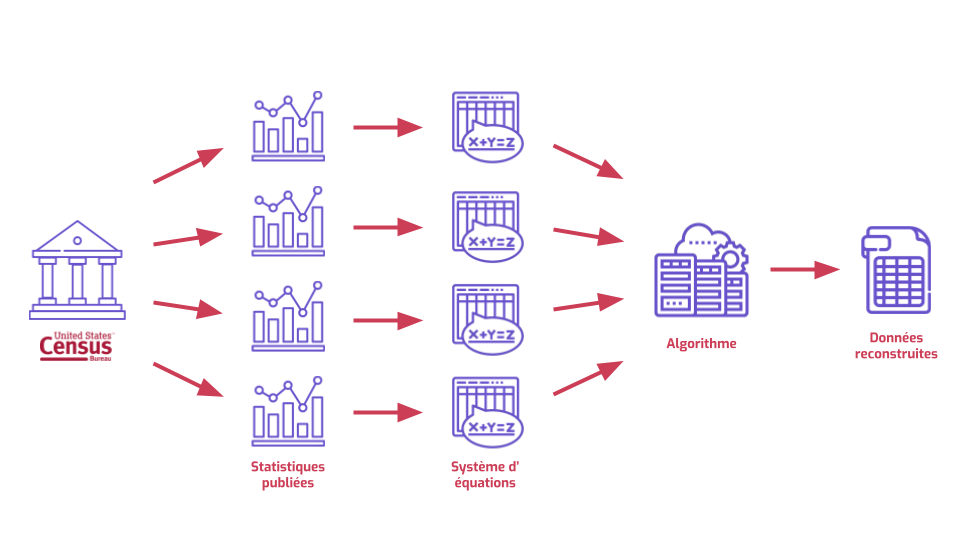
Voilà un truc qu’on peut faire avec une grosse collection de statistiques.
On peut prendre chaque statistique et la voir comme résultat d’une équation à plein d’inconnues. On imagine chaque attribut de chaque individu comme étant une variable, un truc inconnu. Puis on se dit : on sait que la moyenne d’âge dans cette zone géographique, c'est 42,17. Ça veut dire que la somme de tous les âges (inconnus, donc), divisé par le nombre de personnes, c'est exactement 42,17. Et on fait ça pour toutes les statistiques. On obtient un gros système à plein d’inconnues. C’est une sorte d’énigme, un énorme puzzle.
Les puzzles, ça se résout ; les systèmes d’équation aussi. On peut mettre tout ça dans un gros algorithme pour faire ce genre de maths à grande échelle…
Et on obtient des données reconstruites. Un truc qui ressemble fichtrement à la base de données originale : une série d’informations qui correspondent à des individus uniques. Si ces données individuelles ont l’air d’être les mêmes que dans la base de données originale, c’est déjà assez suspect. Mais on peut faire pire.
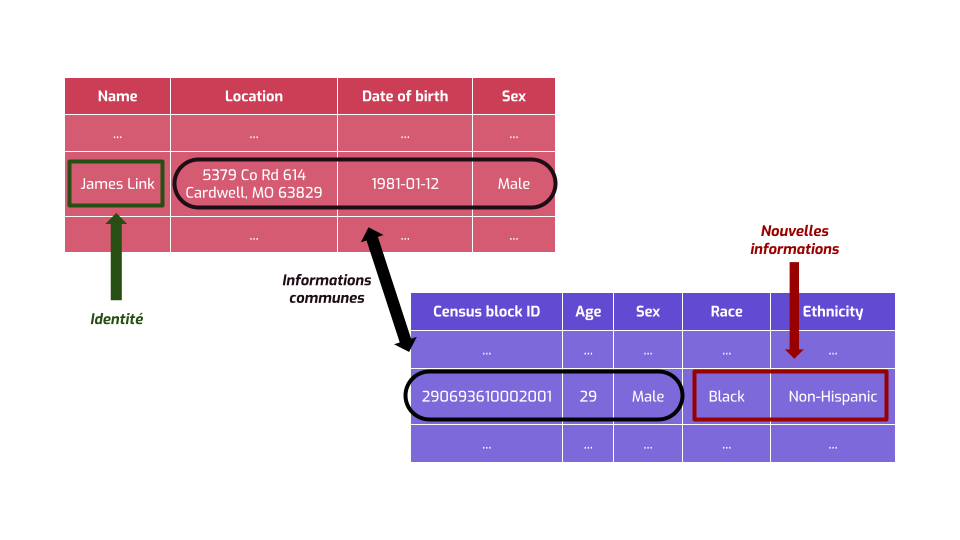
Les données reconstruites ressemblent à la table en bas à droite. On a des informations géographiques et démographiques, mais on a pas de nom.
Mais on peut facilement trouver un autre jeu de données auxiliaires qui contient l’identité de certaines personnes, et certaines informations à leur sujet. Ce genre d’info, plein de gens peuvent l’avoir, par exemple votre employeur, vos connaissances, ou bien les services en ligne que vous utilisez.
On remarque un truc intéressant : certaines informations sont communes aux deux jeux de données. Donc on peut associer chaque ligne de la base de données avec un individu reconstruit à partir des données statistiques.
Mais on a un truc en plus dans les deux bases de données. Dans l’une, on a l’identité de chaque personne…
… dans l’autre, on a des information qu’on avait pas à l’origine. Ça, c’est une mauvaise nouvelle, parce que ça nous permet d’apprendre des informations sensibles, et nouvelles, sur des gens spécifiques.
Au sein le bureau du recensement américain, la possibilité et l’efficacité de cette attaque a été un véritable signal d’alarme. D’autant plus qu’ils avaient quand même essayé de protéger leurs données statistiques, en injectant un peu d’aléatoire dans certaines parties de leur processus. Mais ça a pas suffi.

Donc, c’est une illustration un peu déprimante de la mauvaise nouvelle de tout à l’heure.
Est-ce que tout est perdu ? Est-ce qu’il faut juste arrêter entièrement de publier ou de partager des données si on veut être sûr de ne rien fuiter ? Est-ce que finalement, l’anonymisation, c’est perdu d’avance ? Est-ce qu’on ferait pas mieux d’aller déménager en montagne et élever des chèvres ?
Peut-être pas. Parce que les mathématiciens et cryptologues qui ont formalisé cette vérité fondamentale ont aussi proposé une sorte de “lot de consolation”.

Ce lot de consolation, c’est un moyen mathématique de quantifier et de limiter cette fuite de données personnelles.
On se dit, bon, on peut pas avoir le beurre et l’argent du beurre. En tous cas, pas entièrement. Le mieux qu’on puisse faire, c’est un compromis entre “qu’est-ce qu’on publie comme données globales utiles” et “qu’est ce qu’on fait potentiellement fuiter sur des individus”. Et on peut quantifier ce compromis. On décider du niveau de risque qu’on est prêt à accepter.
On peut faire ça avec une notion qui s’appelle la confidentialité différentielle.
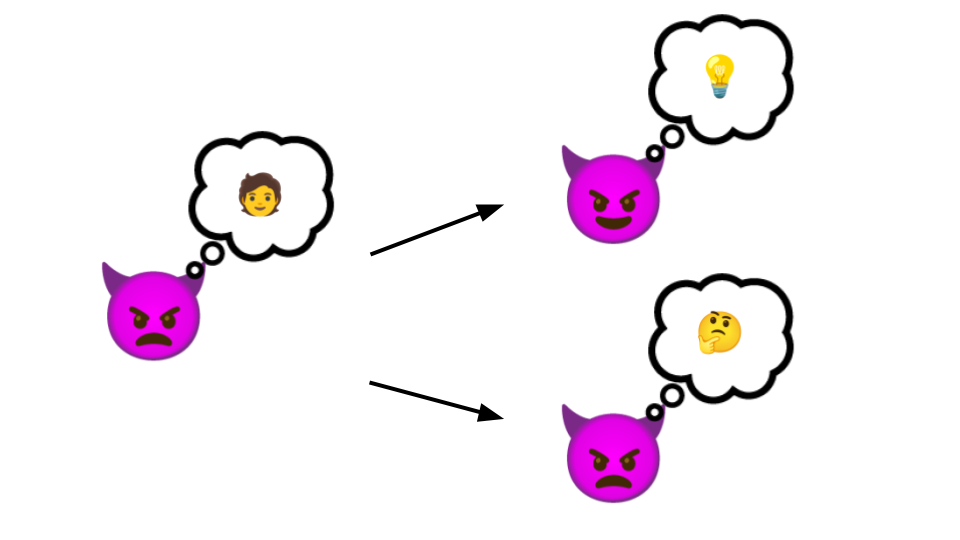
L’intuition de la confidentialité différentielle, c’est de prendre la perspective d’un type méchant qui essaie de deviner une information sur quelqu’un en particulier. Par exemple, est-ce que cette personne spécifique a un cancer. Au début, le type méchant est pas trop sûr si c’est le cas.
Si jamais il regarde le jeu de données qu’on a publié et qu’il peut répondre à cette question avec certitude, c’est une mauvaise nouvelle. On a fait fuiter des informations personnelles. Le type méchant a gagné.
Mais si, après avoir regardé les données qu’on a publié, le type méchant est toujours pas trop sûr de la réponse à sa question, alors c’est bien. Ça veut dire qu’on a pas fait fuiter de données. Enfin, non : on a dit tout à l'heure que c’était pas possible de ne rien faire fuiter. Ça veut dire qu’on a pas trop fait fuiter de données.
Comment on quantifie ça ?
On quantifie ça avec le langage que les mathématiciens utilisent pour parler d’incertitude : avec des probabilités. Ah non zut ! On avait dit « pas de maths ».
On quantifie ça avec le langage que les gens normaux utilisent pour parler d’incertitude : avec des paris sportifs.
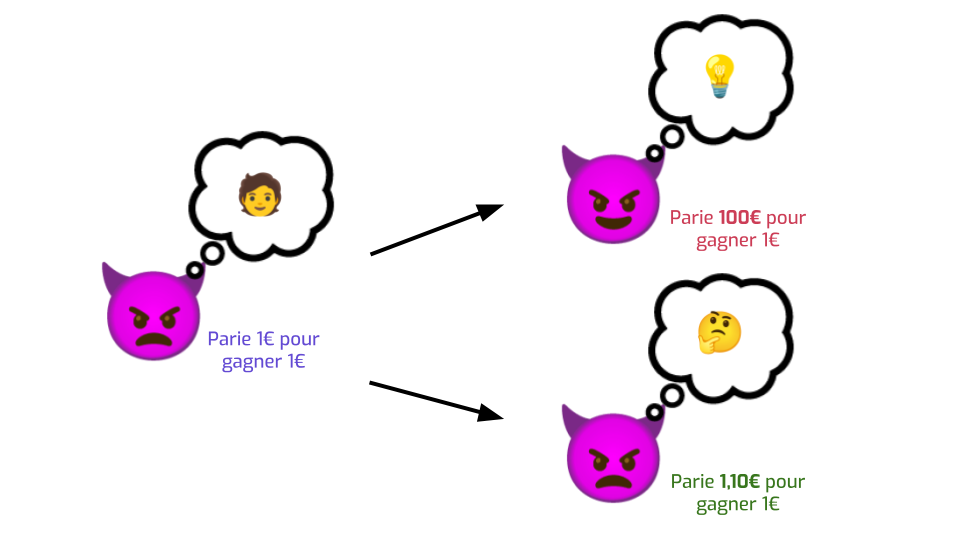
On imagine qu’au début, notre type méchant n'a pas la moindre idée de si sa cible a le cancer ou pas. Si on lui demande de parier sur le sujet, il hausse les épaules, et dit : « Aucune idée. Je vais décider en tirant à pile ou face. Je suis prêt à parier 1€ pour gagner 1€ si j’ai raison ». C’est l’incertitude totale.
Maintenant, ça veut dire quoi si le type méchant a appris de l’information sensible avec un haut degré de certitude ? Ça veut dire qu’il est prêt à parier bien plus qu’il a raison. Il peut dire, par exemple : « Je suis quasiment sûr que ma cible a le cancer. je suis prêt à mettre 100€ sur la table et tout perdre si j’ai tort, tout ça pour ne gagner que 1€ si j’ai raison ».
À l’inverse, si le type méchant n’a pas appris grand-chose, alors il est peut-être prêt à mettre un peu plus sur la table — disons, 1,10€. Il a peut-être une raison d’être légèrement plus suspicieux que sa cible a le cancer, ou ne l’a pas, mais il reste quand même pas trop sûr. Son niveau d’incertitude a diminué, mais pas de beaucoup. Dans ce cas, on peut se dire : « C’est OK, on a pas trop fait fuiter de données ».
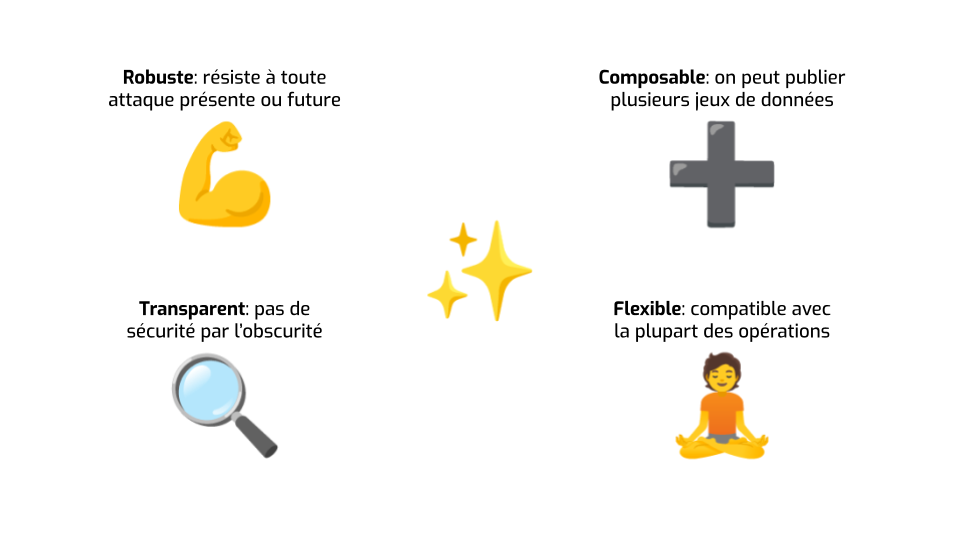
La confidentialité différentielle a plusieurs avantages majeurs.
- D’une part, on ne suppose absolument rien sur le type méchant. La diminution d’incertitude dont je viens de parler correspond au pire des cas : il a accès à toutes les données auxiliaires qu’il veut, un ordinateur surpuissant, etc. On ne fait pas d’hypothèse sur quelle méthode précise il utilise pour arriver à ses fins. C’est du coup une définition très robuste: il n’y a pas de risque que quelqu’un découvre une attaque plus astucieuse dans six mois qui rende obsolète notre méthode d’anonymisation.
- La confidentialité différentielle est la seule définition d’anonymisation qui permet de raisonner sur le risque cumulatif de plusieurs publications. Si je publie des statistiques sur des données une fois, et puis six mois plus tard je publie autre chose qui utilise aussi ces données, je peux quantifier le risque — la diminution d’incertitude du type méchant — des deux publications ensembles.
- La confidentialité différentielle, c’est comme le chiffrement : comme c’est basé sur des maths, on peut être très transparent sur ce qu’on fait exactement aux données pour les protéger. Plus besoin de garder les détails du processus d’anonymisation secrets, comme c’est souvent le cas actuellement.
- Enfin, pas mal de définitions alternatives ne fonctionnent que avec des cas d’utilisation simples, comme des histogrammes. La confidentialité différentielle, ça marche aussi pour faire des choses beaucoup plus compliquées, comme des médianes, du partitionnement de données, des algorithmes d’apprentissage…
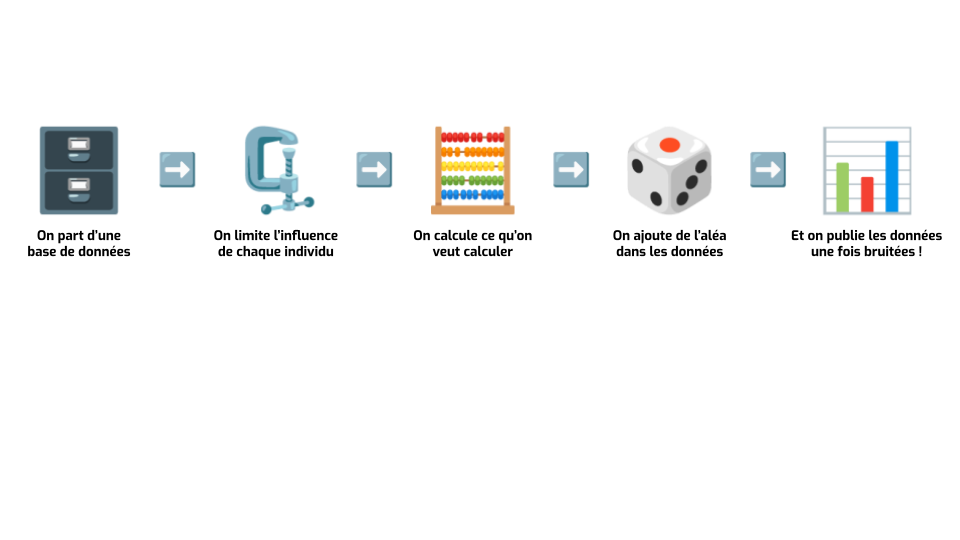
Comment ça marche en pratique ?
C’est un peu comme le chiffrement : les techniques fondamentales reposent sur des maths assez simples, mais ça devient assez vite compliqué. Sans rentrer trop dans les détails, l’immense majorité des techniques qui permettent d’obtenir une propriété de confidentialité différentielle fonctionnent sur le même schéma.
- On commence à partir de nos données sensibles.
- La première étape, c’est de limiter à quel point chaque individu peut contribuer au résultat qu’on veut calculer. Par exemple, si on veut calculer la moyenne des salaires d’un groupe de personnes, il faut limiter le salaire maximal qu’on peut prendre en compte. Sinon, si Bernard Arnault fait partie du jeu de données, ça va être compliqué de cacher cette info.
- Ensuite, on calcule ce qu’on veut calculer — typiquement, des statistiques.
- Puis on va ajouter du bruit dans les données. On peut imaginer qu’on lance un dé et qu’on ajoute le résultat à ce qu’on a calculé jusqu’à maintenant. À la place de publier un salaire moyen de 2800 euros dans une certaine catégorie de la population, on va publier 2816, ou quelque chose de ce genre. L’idée est que le bruit “cache” la contribution de chaque individu. Plus il y a de bruit, moins les statistiques qu’on obtient sont précises, et mieux les gens sont protégés.
- Une fois qu’on a fait tout ça, on peut publier ou partager les données qu’on obtient. Et on peut prouver que chaque individu est correctement protégé.
Je vous donne cette explication pour que vous ayez une idée des grands principes. Mais en pratique, est-ce que c’est ça qu’on fait ? Est-ce qu’on va, à la main, limiter l’influence de chaque individu, calculer des trucs, échantillonner des nombres aléatoires et les ajouter ?
Surtout pas.
La confidentialité différentielle, c’est comme le chiffrement. Même quand, sur le papier, ça n’a pas l’air très compliqué, le diable se cache dans les détails. Il y a un tas de problèmes d’implémentation pénibles avec la génération de nombres aléatoires, le calcul de l’influence de chaque individu pour des opérations compliquées, les imprécisions dûes à l’utilisation de nombres en virgule flottante, et tout un tas d’autres considérations pénibles.
Donc c’est une très mauvaise idée de réimplémenter ça tout seul, et c’est important d’utiliser un des outils conçus et maintenus par des expertes et experts qui prennent en compte et résolvent tous ces problèmes pour vous.
La startup pour laquelle je travaille développe un de ces outils, Tumult Analytics, qu’on utilise avec tous nos clients.
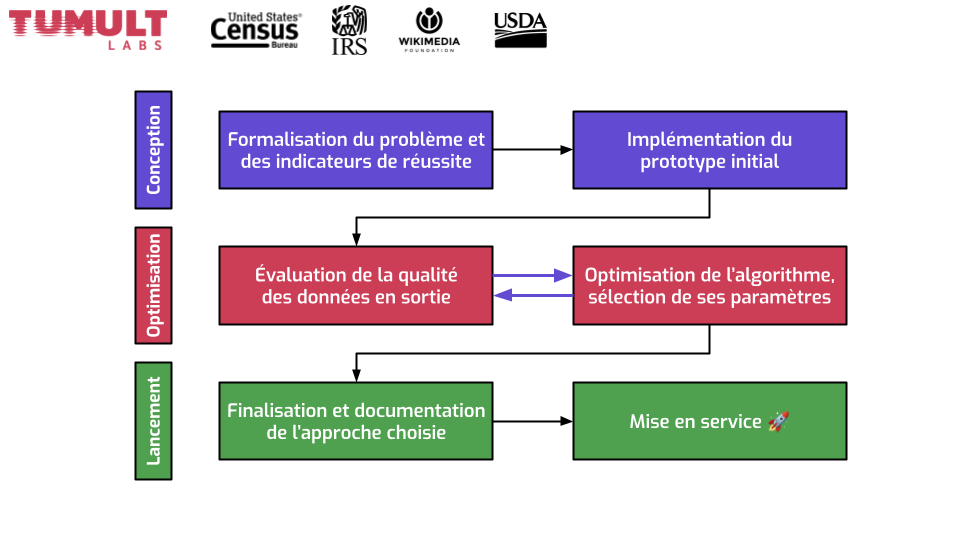
Avec mon employeur, Tumult Labs, on travaille avec plusieurs clients pour les aider à publier des données de façon sécurisée, avec de la confidentialité différentielle. J’ai mis quelques exemples en haut.
Plus qu’un outil, on a développé un processus en plusieurs étapes qu’on reproduit à chaque cas d’utilisation.
- La première grande étape, c’est la conception. On formalise le problème : qu’est-ce qu’on essaie d’accomplir, quel est le but du projet, qui va utiliser les données en sortie. C’est là qu’on définit les indicateurs de réussite. D’un côté, quel est l’objectif de protection de données ? Quel niveau de confidentialité différentielle est acceptable ? Qu’est-ce qu’on essaie de protéger ? De l’autre, on sait qu’on va ajouter du bruit dans les données. Comment quantifier cette imprécision ? Quel type d’imprécision est la plus importante à limiter ? À partir de ces infos, on écrit un premier prototype qui génère les données qu’on veut.
- On passe ensuite à la deuxième grande étape : l’optimisation. On génère des données avec notre prototype, et on regarde — est-ce que le niveau d’imprécision dans les données est acceptable ? Ou bien est-ce qu’il y a trop de bruit, au point que les données ne sont pas utilisables de la façon dont on aimerait ? Quel genre de biais on a introduit ? Généralement, la performance du premier prototype est pas terrible. Il faut donc optimiser notre approche, en changeant certains aspects de l’algorithme, et en sélectionnant des paramètres différents. Observez que les flèches vont dans les deux sens dans cette étape. C’est un processus itératif, où on se rend compte petit à petit de qu’est-ce qui marche bien. Parfois, on se rend compte qu’il y a un critère de succès auquel on avait pas pensé initialement, donc on révise nos indicateurs et on repart pour un tour.
- Enfin, on finit par la phase de lancement, une fois qu’on a déterminé notre algorithme final. On écrit son implémentation, on la teste, on la documente, et on passe le tout en production.
Tout ça paraît peut-être encore un peu abstrait, donc laissez-moi vous donner un exemple du genre de résultat qu'on peut obtenir par l'application de ces méthodes.
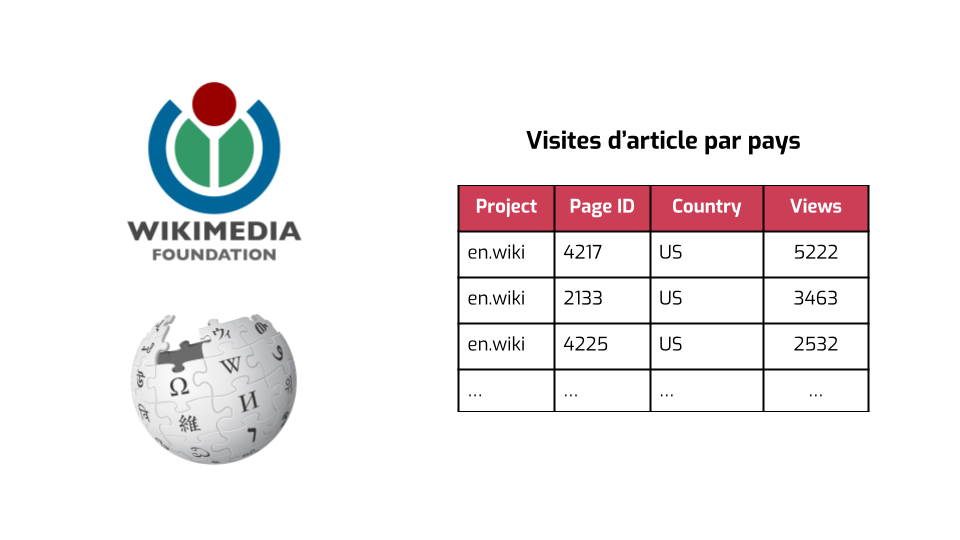
Un de nos clients, c’est la Fondation Wikimédia, qui s’occupe de la gestion de Wikipédia et d’autres projets apparentés, comme Wikidata our le Wiktionnaire.
L’objectif du premier projet sur lequel on a travaillé avec eux, c’était de publier des statistiques du type — chaque jour, pour chaque article de Wikipédia, combien y a-t-il eu de personnes qui ont visité cet article. Avant notre collaboration, la Fondation pouvait ne publier ces statistiques qu’à un niveau global. Les statistiques par pays n’étaient publiées que lorsqu’elles étaient suffisamment grandes, et pas mal de gens — scientifiques, contributeurs, éditrices, etc., — leur avaient demandé de publier plus de données.
Après l'application de notre méthodologie, et en utilisant la bibliothèque logicielle que j'évoquais plus tôt, on a pu leur permettre de publier 40 fois plus de données qu’avant, 250 millions au total (et des centaines de milliers en plus chaque jour). On a aussi pu réduire le seuil auquel on publie des statistiques par un facteur 10, alors même qu’on a une définition d’anonymisation plus robuste.
Pour plus d'infos, vous pouvez consulter l'étude de cas que j'ai écrit à propos de ce project.
À propos d’anonymisation plus robuste. Comme je suis invité par la CNIL, je me suis dit que ça valait peut-être le coup de finir par un sujet peut-être un peu acrobatique…
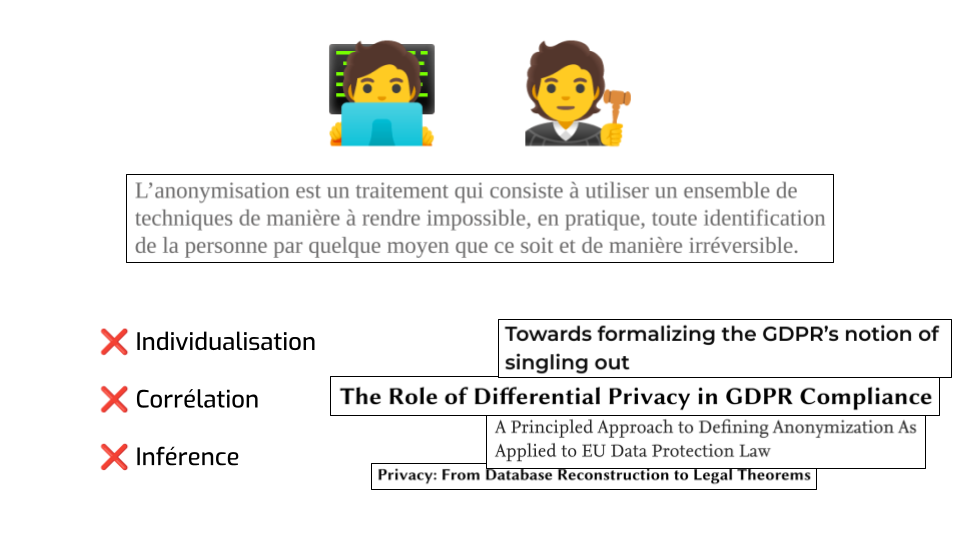
… et c’est parler un peu de l’aspect légal de tout ce que je viens de vous raconter. Comment est-ce que les organismes de régulation définissent l’anonymisation de données ?
Voilà ce que la CNIL dit sur son site web. Il faut que la réidentification soit impossible, par quelque moyen que ce soit. C’est très bien, comme définition. C’est clair, c’est concis, ça ne fait pas dans la demi-mesure. Bon travail. C’est très clairement aligné avec la propriété dont je parlais tout à l’heure : la confidentialité différentielle ne fait pas d’hypothèse sur la façon dont les données pourraient être réidentifiées en théorie, donc on peut compter dessus pour capturer cette impossibilité fondamentale.
Le groupe de travail de l’article 29 précise qu’il faut qu’il y ait trois choses qui soient impossibles à faire avec des données anonymes.
- L’individualisation, c’est le fait de pointer à un morceau de données et d’isoler une personne précise.
- La corrélation, c’est de prendre deux données différentes et de pouvoir dire que ça provient de la même personne.
- L’inférence, c’est d’apprendre une information nouvelle, de façon quasi certaine, sur un individu.
Là encore, c’est assez raisonnable. La partie sur l’inférence a des subtilités qui font que c’est pas si clair, mais je vais pas m’étendre dessus.
Au sein de la communauté des gens qui font de la communauté différentielle, il y a eu plusieurs efforts pour essayer de lier les deux mondes. À la fois expliquer en quoi certaines définitions satisfont (ou pas) ces critères, et les formaliser avec des maths. Il y a un vrai désir de combler l’écart entre les deux mondes, parce qu’on veut que notre travail soit utile au plus grand nombre.

Donc tout ça, c’est super chouette, la collaboration entre les deux mondes est excellente, et il n’y a rien à améliorer.
Sauf que… sauf que les autorités de régulation ne se contentent pas de décrire des buts, elles suggèrent aussi des moyens d’atteindre cet objectif d’anonymisation. Et c'est là que c'est moins enthousiasmant. À la fois dans l’avis du groupe de travail de l’article 29, dans ce qu’on lit sur les sites Web des différentes autorités de protection de données, et dans ce qu’on entend dans des conférences fréquentées par des juristes ou des régulateurs… c’est vraiment pas terrible.
- D’abord, l’exemple typique qui est toujours présenté comme étant une bonne idée, c’est des définitions vieilles de plus de 25 ans, comme le k-anonymat, et ça on sait que c’est complètement cassé en pratique. Donc c’est pas terrible.
- Mais le problème est plus profond: le modèle mental qui est typiquement présenté, c’est un modèle transformatif : on chaque donnée individuelle et on fait quelque chose avec. Par exemple, enlever certaines informations, ajouter du bruit à certaines valeurs, généraliser certaines catégories… Mais on sait que ce genre de mécanisme est très loin d’être robuste. Mieux vaut adopter une stratégie qui agrège des données de plusieurs personnes ensemble, et encourager les gens à publier des statistiques plutôt que des micro-données.
- Il y a aussi un réel manque d’encouragement à faire évoluer les pratiques dans le bon sens. Le RGPD, à l’endroit où il parle de la sécurité du traitement, il dit de prendre en compte “l’état des connaissances”. L’endroit qui définit l’anonymisation dit qu’il faut tenir compte “des technologies disponibles au moment du traitement et de l'évolution de celles-ci”. Et… nous on essaie ! C’est ce qu’on fait toute la journée ! Mais c’est difficile d’avoir l’impression que de votre côté du monde, c’est la même chose. On a pas encore parlé à un client qui nous a dit “on a envie d’adopter la confidentialité différentielle parce que le régulateur nous y encourage”.
Comment on peut faire pour améliorer ça ?

Écoutez, j’y connais rien, donc c’est peut-être super naïf, mais : ça serait bien d’avoir plus de collaborations, et surtout que ces collaborations soient plus transparentes.
J'ai pu voir la différence que ça peut faire en comparant les interactions que j'ai eu avec des organismes publics de régulation d'un côté et de de l'autre de l'Atlantique.
J'ai fait des efforts pour lire ce que les différentes institutions européennes publient au sujet de l'anonymisation, mais ces documents me semblent toujours être mis en ligne à la toute fin du processus, sans qu'il n'y ait d'étape de collection de retours publics. Et quand c'est carrément à côté de la plaque — je pense par exemple à l'étude de cas sur la confidentialité publiée par l'ICO — envoyer des retours et suggestions a l'air d'être complètement inefficace.
Peut-être que je m'y prends mal car je ne connais pas assez ce milieu, mais je sais que les choses peuvent se passer très différemment. NIST, l’organisation pour la standardisation technologique aux USA, a récemment reçu l’ordre du gouvernement américain de publier un guide sur la confidentialité différentielle. Leur processus, c’est d’écrire un brouillon, de publier le brouillon, de demander à toutes les personnes intéressées de leur envoyer des retours et suggestions, d’avoir un gros dialogue pour décider quoi mettre dans la version finale, et de publier le résultat de ce processus.
Donc j’ai passé une semaine sur leur brouillon et je leur ai envoyé plein d’idées, et je vais les rencontrer en visio dans quelques semaines pour discuter de comment améliorer leur guide. Toutes mes contributions vont ensuite tomber dans le domaine public, et je vais pouvoir voir qui d’autre a contribué quelles autres suggestions. Je suis citoyen français, je vis en Europe, donc ça me paraît un peu fou que je puisse avoir une telle influence sur des documents publiés par des organismes américains, mais que l'UE me semble être une boîte noire complète.
Donc ma question ou requête pour vous pour conclure cette présentation, c’est… comment on met en place ce genre d’échange, de collaboration transparente et constructive sur les questions techniques, en Europe ?
Je suis sûr que je ne suis pas le seul intéressé !

Sur ce, merci pour l'invitation, pour votre attention, et d'avance pour vos questions ! Voilà mon adresse mail, et des liens vers mes profils LinkedIn et Mastodon si vous voulez rester en contact.