


4.2.3 System model and design
In this section, we present an overview of the design of our framework, detail the building blocks necessary to implement it, and formally define it as an operator in relational algebra. We finish by providing a proof that the entire process provides user-level differential privacy.
Overview
As suggested in Section 4.2.1.0, we assume that there is a special column of the input dataset that specifies which user owns each row. The system is agnostic to the semantics of this special column. In principle, it can be any unit of privacy that we need to protect: a device identifier, an organization, or even a unique row ID if we want to protect rows and not users. For simplicity of notation we assume that this special column is a user identifier. Users may own multiple rows in each input table, and each row must be owned by exactly one user. Our model guarantees -DP with respect to each user, as defined in Definition 79.
Our DP query engine uses the underlying SQL engine to track user ID metadata across tables, and invokes a DP query rewriter when our anonymization query syntax is used on tables containing user data and any applicable permission checks succeed. Listing 4.5 provides an example of a SQL query accepted by our system.
SELECT WITH ANONYMIZATION T1.partition_key, ANON_SUM(T2.val, 0, 1) FROM Table1 T1 JOIN Table2 T2 USING(uid) GROUP BY T1.partition_key
The query rewriter decomposes such queries into two stages, one before and one after our introduced
DP aggregation operator, invoked with SELECT WITH ANONYMIZATION.
The first stage begins by validating that all table subqueries inside the DP operator’s FROM clause
enforce unique user ownership of intermediate rows, which is informally described in Section 4.2.3.0.
Next, for each row in the subquery result relation, our operator partitions all input rows by the vector of
user-specified GROUP BY keys and the user identifier, and applies an intermediate non-private SQL
aggregation to each group. For example, for ANON_SUM, we use SUM as a partial aggregation.
Adjusting query semantics in this way is necessary to ensure that, in the next stage, the
cross-user aggregations of each partition receive only one input row per user, this is described in
Section 4.2.3.0.
For the second stage, we sample a fixed number of these partially aggregated rows for each user to
limit user contribution across partitions, which is described in Section 4.2.3.0. We then
compute a cross-user DP aggregation across all users contributing to each GROUP BY partition,
limiting user contribution within partitions; this is described in Section 4.2.3.0. Finally, we
randomly drop certain partitions that contain too few users, to guarantee that the list of
published partitions does not break differential privacy guarantees, a process described in
Section 4.2.3.0.
The full process is formalized in Section 4.2.3.0, where we define our operator in the language of relational algebra.
Allowed subqueries
SQL queries can, in principle, contain subqueries that perform arbitrary transformations on the input tables. However, for our framework to guarantee differential privacy, we need to limit this capability: we need the concept of row ownership to stay relevant throughout the computation, and be able to determine which row of the subquery output belongs to which user in the input dataset.
Thus, the relational operators present in the subquery must not create any intermediate objects of shared ownership: no intermediate row may be derived from rows owned by different users. A naive application of certain relational operators violate this requirement. For example, for the aggregation operator, rows owned by distinct users may be aggregated into the same partition. Then the resulting row from that partition will be owned by all users whose data are contributed to the group. For the naive join operator, two rows from distinct users may be joined together, creating a row owned by both users.
This restriction limits our system since some queries cannot be run. We observed that in practice, most use-cases can be fit within these constraints, and leave extensions to a wider class of queries for future work. This might require a different model than the one presented here, but changing query semantics will always be necessary for queries with unbounded sensitivity.
Assume that the column containing user identifier is named uid. We address the shared ownership
issue by restricting each operator composing the subquery such that, for each row in that operator’s
output relation, that row is derived only from rows in the input relation that have matching uid
attributes. We enforce this rule for aggregate operators by requiring that the analyst additionally
groups-by the input relation’s uid attribute. For join operators, we require that the analyst adds a
USING(uid) clause (or equivalent) to the join condition. Additionally, each operator of
must propagate uid from the input relation(s) to the output relation. In queries where this is
unambiguous (i.e., the analyst does not refer to uid in the query), we can automatically propagate
uid.
A formalization of this approach, which list alternatives for each basic operator, is listed in Table 4.3, in Section 4.2.3.0. They are enforced recursively during the query rewrite for each operator that composes the subquery.
Per-user aggregation
First, we aggregate the data of each user per-partition, using the non-private version of the aggregator in
the original query. For example, for ANON_SUM, we use the SUM SQL operator to sum all contributions
of each user in each partition.
This operation guarantees that in the cross-user aggregation stage, each user contributes at most once
to each aggregation. This does come at the cost of introducing another semantic change to the original
query. For example, for ANON_AVG, we end up computing the average of per-user averages, which could
be completely different from the real average of all values. It is easy to create examples of data
distributions in which this difference has a large impact; however, we observed that it does not seem to
introduce significant bias in practical applications.
This step also limits the type of aggregations that can be performed within our framework: for
example, we cannot easily implement ANON_COUNT(DISTINCT col) when col is different from uid
as the per-user aggregation would not contain enough information to combine the contributions of
multiple users (as col values need to be de-duplicated to preserve semantics). We come back to these
considerations in Section 4.3.1.
Stability bounding
Next, to bound the total privacy budget of the computation, we need to ensure that each user contributes to a fixed number of partitions in the output row. To this end, we adapt the notion of query stability from [273].
As an immediate consequence, if a user owns rows in , and is a -stable transformation, then there are at most rows derived from rows owned by in .
Our privacy model requires the input to the cross-user aggregation to have constant stability. Simple SQL operators have a stability of one: for example, each record in an input relation can only be projected onto one record. An addition or a deletion can only affect one record in a projection, so projections have a stability of one. The same logic applies for selection.
Other operators, such as joins, have unbounded stability because source records can be multiplied. Adding or removing a source record can affect an unbounded number of output records. When SQL operators are sequentially composed, we multiply the stability of each operator to yield the entire query’s overall stability. Thus, even a subquery accepted by the checks of Section 4.2.3.0 might not be -stable for any .
To fix this problem, we can compose an unbounded transform with a stability-bounding transform to yield a composite -stable transform:
To define , we use partitioned-by-user reservoir sampling with a per-partition reservoir size of , which has a stability of . Reservoir sampling was chosen for its simplicity, and because it guarantees a strict bound on the contribution of one user. Non-random sampling (e.g. taking the first elements, or using systematic sampling) risks introducing bias in the data, depending on the relative position of records in the dataset. Simple random sampling does not guarantee contribution bounding, and all types of sampling with replacement can also introduce bias in the data.
Joins appear frequently in queries [209], so it is imperative to support them in order for an engine to be practical. Since joins have unbounded stability, a stability bounding mechanism is necessary to provide global stability privacy guarantees on queries with joins. We can thus support a well bounded, full range of join operators.
Bounded-contribution aggregation
Let us now introduce the set of supported -DP statistical aggregates with bounded contribution. These functions are applied after the per-user, per-partition aggregation step discussed in Section 4.2.3.0, and after the stability bounding operator. Importantly, at this step, we assume that each user’s contributions to a single partition have been aggregated to a single input row; this property is enforced by the query rewriter.
COUNT(DISTINCT uid) is the simplest example of an aggregation with bounded contribution: it
counts unique users, so adding or subtracting a user will change the count by no more than 1. For more
complex aggregation functions, we must determine how much a user can contribute to the result and add
appropriately scaled noise. A naive solution without limits on the value of each row leads to unbounded
contribution by a single user. For example, a SUM which can take any real as input has an unbounded
-sensitivity
(see Definition 80).
To address this, each -DP
function accepts an additional pair of lower and upper limit parameters
and
used to clamp (i.e., bound) each input. For example, consider the anonymized sum function
ANON_SUM(col, , ).
Let be the function that transforms each of its inputs into , and then sums all . The global sensitivity for this bounded sum function is:
and thus, ANON_SUM can be defined by using this function and then adding noise scaled by this
sensitivity. A special case of ANON_SUM, widely used in practice, is ANON_COUNT, which is equivalent to
summing 1 for each record present in the dataset.
Once the sensitivity is bounded, noise is added to internal states using the well-known Laplace mechanism (see Section 2.1.6.0) before a differentially private version of the aggregate result is released.
For ANON_AVG, we use the Algorithm 2.4 from [252] (Section 2.5.5): we take
the quotient of a noisy sum (bounded as in ANON_SUM, and scaled by sensitivity
) and a
noisy count. ANON_VAR is similarly derived; we use the same algorithm to compute a bounded mean
and square it, and to compute a mean of bounded squares. ANON_STDDEV is implemented as the square
root of ANON_VAR.
ANON_NTILE, which returns a given percentile of values given as input, is currently based on a
Bayesian binary search algorithm [44, 215], and can be used to define ANON_MIN, ANON_MAX, and
ANON_MEDIAN. The upper and lower bounds are only used to restrict the search space and do not affect
sensitivity. At each iteration of the internal binary search, we count the number of values below and
above the target value, add noise to these two counts, and determine the next step of this binary search
based on these counts. Importantly, this requires to keep all elements in memory, which does not scale
to very large input data. A simple solution, which we implemented, is to randomly sample input
values once we reach a memory limit. Further research is currently underway to find better
options.
For the rest of this section, we assume that contribution bounds are specified as literals in each query to simplify our presentation. Setting bounds requires some prior knowledge about the input set. For instance, to average a column of ages, the lower bound could be reasonably set to and the upper bound to . To enhance usability in the case where there is no such prior knowledge, we also introduce a mechanism for automatically inferring contribution bounds, described in more detail in Section 4.2.5.0.
Table 4.2 lists our suite of aggregate functions. For each function that can be implemented using other functions, we give the equivalent formulation. Note that the equivalent formulation is given using SQL for simplicity, but we do not always implement it via SQL rewriting; we sometimes implement them as standalone low-level aggregators and only reuse the code for other aggregators. We come back to these implementation considerations in Section 4.3.1.
| Function | Equivalent formulation |
ANON_SUM(col, L, U) | |
ANON_COUNT(col, U) | ANON_SUM(1, 0, U)1 |
ANON_COUNT(DISTINCT uid) | ANON_COUNT(uid, 1) |
ANON_AVG(col, L, U) | 2 |
| ANON_VAR(col, L, U) | ANON_SUM(col*col, 0, MAX(L*L,U*U)) - ANON_SUM(col, L, U)^23 |
ANON_STDDEV(col, L, U) | SQRT(ANON_VAR(col, L, U)) |
ANON_NTILE(col, ntile, L, U) | 4 |
ANON_MIN(col, L, U) | ANON_NTILE(col, 0, L, U) |
ANON_MAX(col, L, U) | ANON_NTILE(col, 1, L, U) |
ANON_MEDIAN(col, L, U) | ANON_NTILE(col, 0.5, L, U) |
1 Technically, ANON_SUM(IF col IS NOT NULL THEN 1 ELSE 0, 0, U).
2 This could be formulated as ANON_SUM(col, L, U) / ANON_COUNT(col, U’) for a well-chosen U’. However, the choice of U’ makes this
option undesirable, so we implement ANON_AVGseparately instead; see the extended discussion in Section 4.3.1.0.
3 Note that the per-user aggregation step for ANON_VARis not VAR; we give more details about this case in Section 4.3.1.0.
4 We discuss this aggregation in more detail in Section 4.3.1.0.
Minimum user threshold
In this section, we outline a technique proposed in [230] to prevent the presence of
arbitrary partitions (GROUP BY keys) in a query from violating the privacy predicate: the
-thresholding
mechanism. For example, consider the naive implementation in Listing 4.6.
SELECT col1, ANON_SUM(col2, L, U) FROM Table GROUP BY col1
Suppose that for the value
To prevent this, for each result aggregation row, we calculate an
-DP
count of unique contributing users. If that count is less than some minimum user threshold
, the result row is
discarded. is chosen by
our model based on ,
, and
parameter values. In the example above, the output row for group
The choice of depends on , , and ;
If an SQL query:
-
guarantees that each user appears in at most partitions;
-
for each partition, computes and releases an -DP noisy count of the number of contributing users using the Laplace mechanism;
-
does not release anything for empty partitions;
-
and only releases counts greater or equal than ;
then it provides user-level -DP.
Proof. First, note that that if a dataset contains a single row, then the probability that an -DP noisy count of the number of rows in will yield at least for any is
Indeed, this is a special case of Section 5.2 in [230]: the noisy count is distributed as the Laplace distribution centered at the true count of with scale parameter . Evaluating the CDF at yields .
Let us now prove the main statement. Let be the SQL operation described in the theorem. Consider any pair of datasets such that and such that the set of non-empty groups from is the same as that for ; call this set . The -DP noisy count will get invoked for all groups in for both datasets, and the -thresholding applied. For all groups not in , no row will be released for both datasets. A change in the user may affect a maximum of output counts, each of which is -DP, so by the composition property of differential privacy (see Proposition 5), we have:
Next, consider an empty dataset . Let be the set of all outputs and let be the output set containing only the output “no result rows are produced”. Then we have . It remains to show that for dataset containing a single user, . The -DP count is computed by counting the number of rows, and then adding Laplace noise with scale . Dataset contains values for a maximum of groups; it is only possible to produce an output row for those groups. For each groups, the probability that the noisy count will be at least is , by the initial observation. Then:
so we need to satisfy:
Solving for in the expression :
Lastly, consider SQL engine operator and datasets such that is with the addition of a single user. It remains to consider the case where and do not have the same set of non-empty groups. Since they differ by one user, may have a maximum of additional non-empty groups, each containing unique user; call this set of groups . Call the set of the remaining groups . Split the rows of into two datasets: the rows that correspond to groups in and , respectively. Call the rows of that correspond to groups as and the rows that correspond to groups as . Note that only contains rows corresponding to groups . Now, split the operator into two operators and : is with an added filter that only outputs result rows corresponding groups in ; is the same for .
We have decomposed our problem into the previous two cases. The system of , , and is the case where the pair of datasets have the same set of non-empty groups, . The system of , the empty dataset, and is the case where the non-empty dataset contains a single user. Each system satisfies the DP predicate separately. Since they operate on a partition of all groups in and , the two systems satisfy the DP predicate when recombined into , , and .
We have shown that for two datasets differing by a single user, the DP predicate is satisfied. Thus, we have shown that our SQL query provides user-level -DP. □
Note that this operation must be taken into account as part of privacy budget computation. If the only
operation that the user requested was ANON_COUNT(DISTINCT uid), then we can simply post-process
the results of this noisy aggregation to threshold the output. Otherwise, we have to add this aggregation
alongside the requested ones in the query rewriter, and split the budget between all these
operations.
Query semantics
In this section, we formally define our -DP relational operator, denoted by , using some of the conventional operators in relational algebra. This is simply a reformulation than the process described in Section 4.2.3 so far.
First, let us quickly recall standard operators in relational algebra, used to describe the transformations on datasets that occur in a query.
-
: project columns from .
-
: select from satisfying the predicate .
-
: group on the cross products of distinct keys in the columns in ; apply the aggregations in to each group.
-
: take the cross product of rows in and , and select only the rows that satisfy the predicate .
Let (select-list), (group-list), and (aggregate-list) denote the attribute names , , and , respectively. Assume is restricted to only contain the -DP aggregate function calls discussed in Section 4.2.3.0. Our introduced operator, , can be interpreted as an anonymized grouping and aggregation operator with similar semantics to , and supports queries in the general form given in Listing 4.7.
SELECT WITH ANONYMIZATION , FROM (R) GROUP BY
First, verifies row ownership constraints on : it must not contain any additional analyst-specified operators which create intermediate objects of shared ownership, as defined in Section 4.2.3.0. Formally, imposes that all operators present in this subquery are allowed, as defined by Table 4.3.
| Operator | Basic form | Required variant |
| Projection | ||
| Selection | ||
| Aggregation | ||
| Join | ||
If
is an input table where each row is owned by exactly one user, and
satisfies those constraints,
then this guarantees that
also has such a user identifier uid in its schema. We can then use
as the input to our
proposed operator ,
and define our query :
The query rewriter discussed in Section 4.2.3.0 transforms a query containing into a query that only contains SQL primitives, minimizing the number of changes to the underlying SQL engine. We define the following in order to express our rewriting operation.
-
Let denote the number of user IDs present in a given partition. In SQL, it would be expressed as
COUNT(DISTINCT uid). We use it in the condition , which captures the -thresholding mechanism introduced in Section 4.2.2.0 and discussed in more detail in Section 4.2.3.0. -
Let be the corresponding non--DP partial aggregation functions of . For example, if is
ANON_SUM, would beSUM. -
Let behave like a reservoir-sampling SQL
TABLESAMPLEoperator where is the grouping list and is the number of samples per group. In other words, the operation partitions by columns . For each partition, it randomly samples up to rows. We use as this stability-bounding operator, discussed in Section 4.2.3.0.
When the query rewriter is invoked on the following relational expression containing :
it returns the modified expression, with expanded:
Effectively, the rewriter splits into the two-stage aggregation and .
-
groups the output of by the key vector , applying the partial aggregation functions to each group. rows are then sampled for each user. The first aggregation enforces that there is only one row per user per partition during the next aggregation step.
-
performs a second, differentially private, aggregation over the output of . This aggregation groups only by the keys in and applies the -DP aggregation functions . These functions assume that every user contributes at most one input row. A filter operator is applied last to suppress any rows with too few contributing users.
Together, this implements the process described in the previous parts of Section 4.2.3.
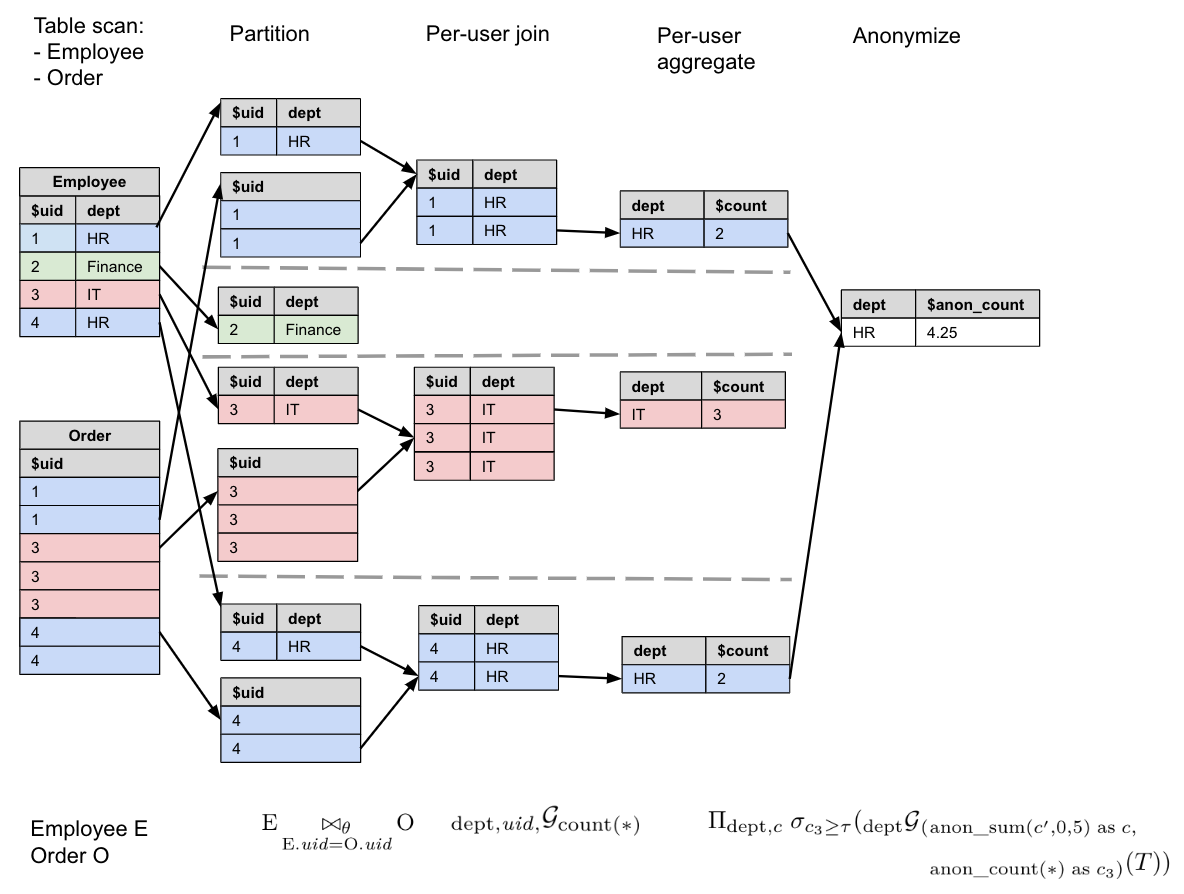
Let us illustrate this process with a concrete example. Consider the following query. It assumes we have an Employee table and an Order table, which both have a field, and it is counting the number of orders made by employees in each department.
SELECT WITH ANONYMIZATION dept, ANON_COUNT(*, 5) AS c FROM Employee E JOIN Order O USING(uid) GROUP BY dept
Recall that ANON_COUNT(*, U) is equivalent to ANON_SUM(col, 0, U) in the cross-user
aggregation step. We can express this query in relational algebra using our DP operator
:
Let us expand into the two-stage aggregation, and , and let us call the initial table subquery. Our query can then be written as:
Note that we add an additional user counting
-DP function, aliased as
, which is compared to our threshold
parameter, , to ensure that the
grouping does not violate the -DP
predicate, to be discussed in Section 4.2.3.0. In this case
is the
number of unique users in each department: as each user contributes at most 1 to each partition, we can
simply use ANON_COUNT(*) to compute this count of unique users.
In Figure 4.9, we illustrate the workflow with example tables Employee and Order,
, and
.
User-level differential privacy
In this section, we show that our engine satisfies user-level -DP, as defined in Section 4.2.1.0.
Suppose that a query has aggregate function list , and grouping list . Let the privacy parameter for aggregation function be .
Consider any set of rows owned by a single user in the input relation of our anonymization operator, . We first partition and aggregate these rows by the key vector , before sampling up to rows for each partition by .
The result for a group is reported if the -thresholding predicate defined in Section 4.2.3.0 is satisfied. Computing and reporting the comparison count for this predicate is -DP. For , such that they differ by a user’s data for a single group , consider each aggregation function as applied to group . By composition theorems and Theorem 12, we provide user-level -DP for that row.
However, there are many groups in a given query. Due to our stability bounding mechanism, a single user can contribute to up to groups. The output rows corresponding to these groups can be thought of as the result of sequentially composed queries. Let such that . Let be the sum of the greatest elements in the set . Again, by composition, we conclude that for any output set , and some , we have
This shows that given engine-defined parameters , , and , it is possible to set privacy parameters for individual -DP functions to satisfy the query -DP predicate. For example, we can set and to for all and . is enforced by the derived parameter as discussed in Section 4.2.3.0. Both user-privacy parameters and can therefore be bounded to be arbitrarily small by analysts and data owners.
Note that the method we use to guarantee user-level differential privacy can be interpreted as similar to row-level group privacy: after the per-user aggregation step, we use the composition theorem to provide group privacy for a group of size . Alone, row-level group privacy does not provide user-level privacy, but in combination to user-level contribution bounding, this property is sufficient to obtain the desired property.